

Chapter 8 : Array Columns¶
Chapter Learning Objectives¶
Various data operations on columns containing date strings, date and timestamps.
Chapter Outline¶
1. How to deal with Array columns?
1d. How to find the list of elements in column A, but not in column B without duplicates?
1f. How to create an array from a column value repeated many times?
1g. How to remove all elements equal to an element from the given array in a column?
1k. How to convert a column of nested arrays into a map column?
1l. How to sort an array in a column in ascending or descending order?
1o. How to create a array column containing elements with sequence(start, stop, step)?
1p. How to reverse the order(not reverse sort) of an array in a column ?
1u. How to concatenate the elements of an array in a column?
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
from IPython.display import display_html
import pandas as pd
import numpy as np
def display_side_by_side(*args):
html_str=''
for df in args:
html_str+=df.to_html(index=False)
html_str+= "\xa0\xa0\xa0"*10
display_html(html_str.replace('table','table style="display:inline"'),raw=True)
space = "\xa0" * 10
import panel as pn
css = """
div.special_table + table, th, td {
border: 3px solid orange;
}
"""
pn.extension(raw_css=[css])
1a. How to create a array column from multiple columns?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.array(*cols)
Creates a new array column.
Parameters
cols – list of column names (string) or list of Column expressions that have the same data type.
‘’’
Input: Spark data frame with multiple columns
df_mul = spark.createDataFrame([('John', 'Seattle', 60, True, 1.7, '1960-01-01'),
('Tony', 'Cupertino', 30, False, 1.8, '1990-01-01'),
('Mike', 'New York', 40, True, 1.65, '1980-01-01')],['name', 'city', 'age', 'smoker','height', 'birthdate'])
df_mul.show()
+----+---------+---+------+------+----------+
|name| city|age|smoker|height| birthdate|
+----+---------+---+------+------+----------+
|John| Seattle| 60| true| 1.7|1960-01-01|
|Tony|Cupertino| 30| false| 1.8|1990-01-01|
|Mike| New York| 40| true| 1.65|1980-01-01|
+----+---------+---+------+------+----------+
Output : Spark data frame with a array column
from pyspark.sql.functions import array
df_array = df_mul.select(array(df_mul.age,df_mul.height,df_mul.city).alias("array_column"))
df_array.show()
+--------------------+
| array_column|
+--------------------+
| [60, 1.7, Seattle]|
|[30, 1.8, Cupertino]|
|[40, 1.65, New York]|
+--------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_mul.toPandas(),df_array.toPandas())
Input Output
| name | city | age | smoker | height | birthdate |
|---|---|---|---|---|---|
| John | Seattle | 60 | True | 1.70 | 1960-01-01 |
| Tony | Cupertino | 30 | False | 1.80 | 1990-01-01 |
| Mike | New York | 40 | True | 1.65 | 1980-01-01 |
| array_column |
|---|
| [60, 1.7, Seattle] |
| [30, 1.8, Cupertino] |
| [40, 1.65, New York] |
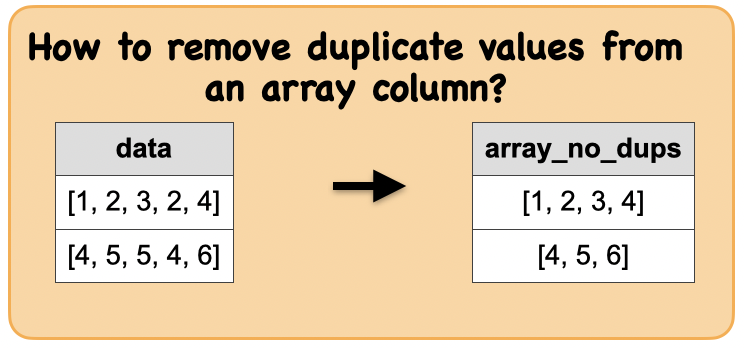
1b. How to remove duplicate values from an array column?¶
Lets first understand the syntax
Syntax
ppyspark.sql.functions.array_distinct(col)
removes duplicate values from the array
Parameters:
col – name of column or expression ‘’’
Input: Spark data frame with a array column with duplicates
df_array = spark.createDataFrame([([1, 2, 3, 2, 4],), ([4, 5, 5, 4, 6],)], ['data'])
df_array.show()
+---------------+
| data|
+---------------+
|[1, 2, 3, 2, 4]|
|[4, 5, 5, 4, 6]|
+---------------+
Output : Spark data frame with a array column with no duplicates
from pyspark.sql.functions import array_distinct
df_array_no = df_array.select(array_distinct(df_array.data).alias("array_no_dup"))
df_array_no.show()
+------------+
|array_no_dup|
+------------+
|[1, 2, 3, 4]|
| [4, 5, 6]|
+------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_array.toPandas(),df_array_no.toPandas())
Input Output
| data |
|---|
| [1, 2, 3, 2, 4] |
| [4, 5, 5, 4, 6] |
| array_no_dup |
|---|
| [1, 2, 3, 4] |
| [4, 5, 6] |
1c. How to check if a value is in an array column?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.array_contains(col, value)
returns null if the array is null, true if the array contains the given value, and false otherwise.
Parameters:
col – name of column containing array
value – value or column to check for in array
‘’’
Input: Spark data frame with a array column
df1 = spark.createDataFrame([([1, 2, 3],), ([],),([None, None],)], ['data'])
df1.show()
+---------+
| data|
+---------+
|[1, 2, 3]|
| []|
| [,]|
+---------+
Output : Spark data frame with a column to indicate if a value exists
from pyspark.sql.functions import array_contains
df2 = df1.select(array_contains(df1.data, 1).alias("if_1_exists"))
df2.show()
+-----------+
|if_1_exists|
+-----------+
| true|
| false|
| null|
+-----------+
Summary:
print("input ", "output")
display_side_by_side(df1.toPandas(),df2.toPandas())
input output
| data |
|---|
| [1, 2, 3] |
| [] |
| [None, None] |
| if_1_exists |
|---|
| True |
| False |
| None |
1d. How to find the list of elements in column A, but not in column B without duplicates?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.array_except(col1, col2)
returns an array of the elements in col1 but not in col2, without duplicates.
Parameters
col1 – name of column containing array
col2 – name of column containing array ‘’’
Input: Spark data frame with 2 array columns
df3 = spark.createDataFrame([([1, 2, 3, 4, 5],[6, 7, 8, 9, 10]), ([4, 5, 5, 4, 6],[6, 2, 3, 2, 4])], ['A', 'B'])
df3.show()
+---------------+----------------+
| A| B|
+---------------+----------------+
|[1, 2, 3, 4, 5]|[6, 7, 8, 9, 10]|
|[4, 5, 5, 4, 6]| [6, 2, 3, 2, 4]|
+---------------+----------------+
Output : Spark data frame with a result array column
from pyspark.sql.functions import array_except
df4 = df3.select(array_except(df3.A, df3.B).alias("in_A_not_in_B"))
df4.show()
+---------------+
| in_A_not_in_B|
+---------------+
|[1, 2, 3, 4, 5]|
| [5]|
+---------------+
Summary:
print("Input ", "Output")
display_side_by_side(df3.toPandas(),df4.toPandas())
Input Output
| A | B |
|---|---|
| [1, 2, 3, 4, 5] | [6, 7, 8, 9, 10] |
| [4, 5, 5, 4, 6] | [6, 2, 3, 2, 4] |
| in_A_not_in_B |
|---|
| [1, 2, 3, 4, 5] |
| [5] |
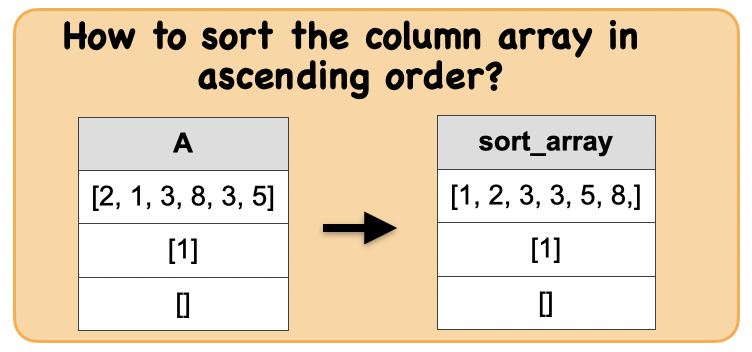
1e.How to sort the column array in ascending order?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.array_sort(col)
sorts the input array in ascending order. The elements of the input array must be orderable. Null elements will be placed at the end of the returned array.
Parameters
col – name of column or expression ‘’’
Input: Spark data frame with an array column
df_arr = spark.createDataFrame([([2, 1, None, 3, 8, 3, 5],),([1],),([],)], ['data'])
df_arr.show()
+-------------------+
| data|
+-------------------+
|[2, 1,, 3, 8, 3, 5]|
| [1]|
| []|
+-------------------+
Output : Spark data frame with a sorted array column
from pyspark.sql.functions import array_sort
df_sort =df_arr.select(array_sort(df_arr.data).alias('sort'))
df_sort.show()
+-------------------+
| sort|
+-------------------+
|[1, 2, 3, 3, 5, 8,]|
| [1]|
| []|
+-------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_arr.toPandas(),df_sort.toPandas())
Input Output
| data |
|---|
| [2, 1, None, 3, 8, 3, 5] |
| [1] |
| [] |
| sort |
|---|
| [1, 2, 3, 3, 5, 8, None] |
| [1] |
| [] |
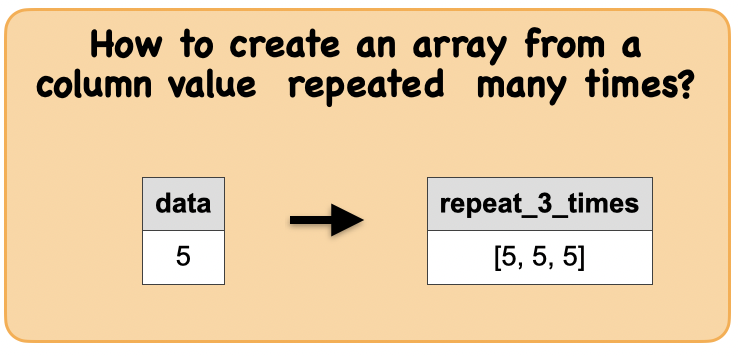
1f. How to create an array from a column value repeated many times?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.array_repeat(col, count)
Collection function: creates an array containing a column repeated count times.
‘’’
Input: Spark data frame with a column
df_val = spark.createDataFrame([(5,)], ['data'])
df_val.show()
+----+
|data|
+----+
| 5|
+----+
Output : Spark data frame with a column of array of repeated values
from pyspark.sql.functions import array_repeat
df_repeat = df_val.select(array_repeat(df_val.data, 3).alias('repeat'))
df_repeat.show()
+---------+
| repeat|
+---------+
|[5, 5, 5]|
+---------+
Summary:
print("Input ", "Output")
display_side_by_side(df_val.toPandas(),df_repeat.toPandas())
Input Output
| data |
|---|
| 5 |
| repeat |
|---|
| [5, 5, 5] |
1g. How to remove all elements equal to an element from the given array in a column?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.array_remove(col, element)
Remove all elements that equal to element from the given array.
Parameters
col – name of column containing array
element – element to be removed from the array
‘’’
Input: Spark data frame with an array column
df_arr2 = spark.createDataFrame([([1, 2, 3, 8, 4],), ([4, 5, 32, 32, 6],)], ['data'])
df_arr2.show()
+-----------------+
| data|
+-----------------+
| [1, 2, 3, 8, 4]|
|[4, 5, 32, 32, 6]|
+-----------------+
Output : Spark data frame with an array column with an element removed
from pyspark.sql.functions import array_remove
df_arr3 = df_arr2.select(array_remove(df_arr2.data, 4).alias("array_remove_4"))
df_arr3.show()
+--------------+
|array_remove_4|
+--------------+
| [1, 2, 3, 8]|
|[5, 32, 32, 6]|
+--------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_arr2.toPandas(),df_arr3.toPandas())
Input Output
| data |
|---|
| [1, 2, 3, 8, 4] |
| [4, 5, 32, 32, 6] |
| array_remove_4 |
|---|
| [1, 2, 3, 8] |
| [5, 32, 32, 6] |
1h . How to locate the position of first occurrence of the given value in the given array in a column?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.array_position(col, value)
Collection function: Locates the position of the first occurrence of the given value in the given array. Returns null if either of the arguments are null.
‘’’
Input: Spark data frame with an array column
df_pos1 = spark.createDataFrame([([1, 2, 3, 8, 4],), ([4, 5, 32, 32, 6],)], ['data'])
df_pos1.show()
+-----------------+
| data|
+-----------------+
| [1, 2, 3, 8, 4]|
|[4, 5, 32, 32, 6]|
+-----------------+
Output : Spark data frame with column giving the position of the element
from pyspark.sql.functions import array_position
df_pos2 = df_pos1.select(array_position(df_pos1.data, 4).alias("array_position_4"))
df_pos2.show()
+----------------+
|array_position_4|
+----------------+
| 5|
| 1|
+----------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_pos1.toPandas(),df_pos2.toPandas())
Input Output
| data |
|---|
| [1, 2, 3, 8, 4] |
| [4, 5, 32, 32, 6] |
| array_position_4 |
|---|
| 5 |
| 1 |
1i. How to find the minimum value of an array in a column?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.array_min(col)
returns the minimum value of the array.
Parameters
col – name of column or expression ‘’’
Input: Spark data frame with an array columns
df_arr = spark.createDataFrame([([1, 2, 3, 8, 4],), ([4, 5, 32, 32, 6],)], ['data'])
df_arr.show()
+-----------------+
| data|
+-----------------+
| [1, 2, 3, 8, 4]|
|[4, 5, 32, 32, 6]|
+-----------------+
Output : Spark data frame with a column
from pyspark.sql.functions import array_min
df_min = df_arr.select(array_min(df_arr.data).alias("array_min"))
df_min.show()
+---------+
|array_min|
+---------+
| 1|
| 4|
+---------+
Summary:
print("Input ", "Output")
display_side_by_side(df_arr.toPandas(),df_min.toPandas())
Input Output
| data |
|---|
| [1, 2, 3, 8, 4] |
| [4, 5, 32, 32, 6] |
| array_min |
|---|
| 1 |
| 4 |
1j. How to find the maximum value of an array in a column?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.array_max(col)
returns the maximum value of the array.
Parameters
col – name of column or expression ‘’’
Input: Spark data frame with an array column
df = spark.createDataFrame([([1, 2, 3, 8, 4],), ([4, 5, 32, 32, 6],)], ['data'])
df.show()
+-----------------+
| data|
+-----------------+
| [1, 2, 3, 8, 4]|
|[4, 5, 32, 32, 6]|
+-----------------+
Output : Spark data frame with a column
from pyspark.sql.functions import array_max
df_max = df.select(array_max(df.data).alias("array_max"))
df_max.show()
+---------+
|array_max|
+---------+
| 8|
| 32|
+---------+
Summary:
print("input ", "output")
display_side_by_side(df.toPandas(),df_max.toPandas())
input output
| data |
|---|
| [1, 2, 3, 8, 4] |
| [4, 5, 32, 32, 6] |
| array_max |
|---|
| 8 |
| 32 |
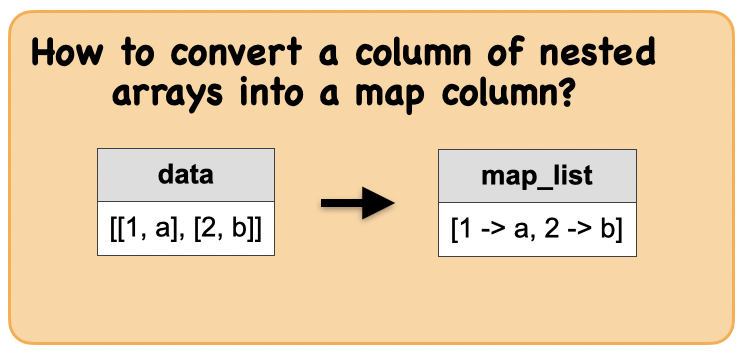
1k. How to convert a column of nested arrays into a map column?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.map_from_arrays(col1, col2)
Creates a new map from two arrays.
Parameters
col1 – name of column containing a set of keys. All elements should not be null
col2 – name of column containing a set of values
‘’’
Input: Spark data frame with a map column
df = spark.sql("SELECT array(struct(1, 'a'), struct(2, 'b')) as data")
df.show()
+----------------+
| data|
+----------------+
|[[1, a], [2, b]]|
+----------------+
Output : Spark data frame with a date column
from pyspark.sql.functions import map_from_entries
df_map = df.select(map_from_entries("data").alias("map"))
df_map.show()
+----------------+
| map|
+----------------+
|[1 -> a, 2 -> b]|
+----------------+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_map.toPandas())
Input Output
| data |
|---|
| [(1, a), (2, b)] |
| map |
|---|
| {1: 'a', 2: 'b'} |
1l. How to sort an array in a column in ascending or descending order?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.sort_array(col, asc=True)
sorts the input array in ascending or descending order according to the natural ordering of the array elements. Null elements will be placed at the beginning of the returned array in ascending order or at the end of the returned array in descending order.
Parameters
col – name of column or expression ‘’’
Input: Spark data frame with an array column
df = spark.createDataFrame([([1, 2, 3, 8, 4],), ([4, 5, 32, 32, 6],)], ['data'])
df.show()
+-----------------+
| data|
+-----------------+
| [1, 2, 3, 8, 4]|
|[4, 5, 32, 32, 6]|
+-----------------+
Output : Spark data frame with a sorted array column
from pyspark.sql.functions import sort_array
df_asc = df.select(sort_array(df.data, asc=True).alias('asc'))
df_asc.show()
+-----------------+
| asc|
+-----------------+
| [1, 2, 3, 4, 8]|
|[4, 5, 6, 32, 32]|
+-----------------+
from pyspark.sql.functions import sort_array
df_desc = df.select(sort_array(df.data, asc=False).alias('desc'))
df_desc.show()
+-----------------+
| desc|
+-----------------+
| [8, 4, 3, 2, 1]|
|[32, 32, 6, 5, 4]|
+-----------------+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_asc.toPandas(), df_desc.toPandas())
Input Output
| data |
|---|
| [1, 2, 3, 8, 4] |
| [4, 5, 32, 32, 6] |
| asc |
|---|
| [1, 2, 3, 4, 8] |
| [4, 5, 6, 32, 32] |
| desc |
|---|
| [8, 4, 3, 2, 1] |
| [32, 32, 6, 5, 4] |
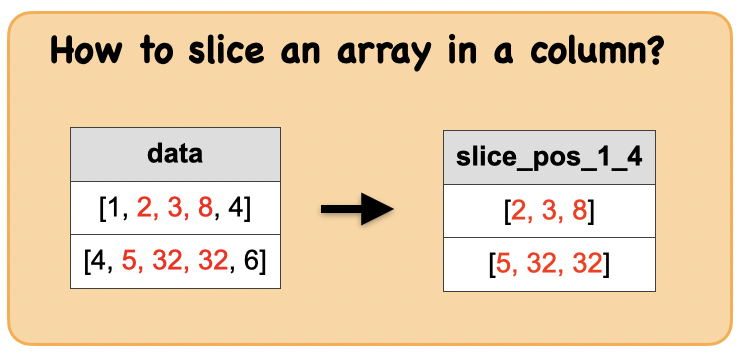
1m. How to slice an array in a column?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.map_from_arrays(col1, col2)
Creates a new map from two arrays.
Parameters
col1 – name of column containing a set of keys. All elements should not be null
col2 – name of column containing a set of values
‘’’
Input: Spark data frame with an array column
df = spark.createDataFrame([([1, 2, 3, 8, 4],), ([4, 5, 32, 32, 6],)], ['data'])
df.show()
+-----------------+
| data|
+-----------------+
| [1, 2, 3, 8, 4]|
|[4, 5, 32, 32, 6]|
+-----------------+
Output : Spark data frame with an array column
from pyspark.sql.functions import slice
df.select(slice(df.data, 2, 3).alias('slice')).show()
+-----------+
| slice|
+-----------+
| [2, 3, 8]|
|[5, 32, 32]|
+-----------+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_map.toPandas())
Input Output
| data |
|---|
| [1, 2, 3, 8, 4] |
| [4, 5, 32, 32, 6] |
| map |
|---|
| {1: 'a', 2: 'b'} |
1n. How to shuffle a column containing an array?¶

Syntax
pyspark.sql.functions.shuffle(col)
Generates a random permutation of the given array.
‘’’
Input: Spark data frame with an array column
df = spark.createDataFrame([([1, 2, 3, 8, 4],), ([4, 5, 32, 32, 6],)], ['data'])
df.show()
+-----------------+
| data|
+-----------------+
| [1, 2, 3, 8, 4]|
|[4, 5, 32, 32, 6]|
+-----------------+
Output : Spark data frame with shuffled array column
from pyspark.sql.functions import shuffle
df_shu = df.select(shuffle(df.data).alias('shuffle'))
df_shu.show()
+-----------------+
| shuffle|
+-----------------+
| [4, 8, 3, 2, 1]|
|[32, 6, 4, 32, 5]|
+-----------------+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_shu.toPandas())
Input Output
| data |
|---|
| [1, 2, 3, 8, 4] |
| [4, 5, 32, 32, 6] |
| shuffle |
|---|
| [4, 8, 3, 2, 1] |
| [32, 6, 4, 32, 5] |
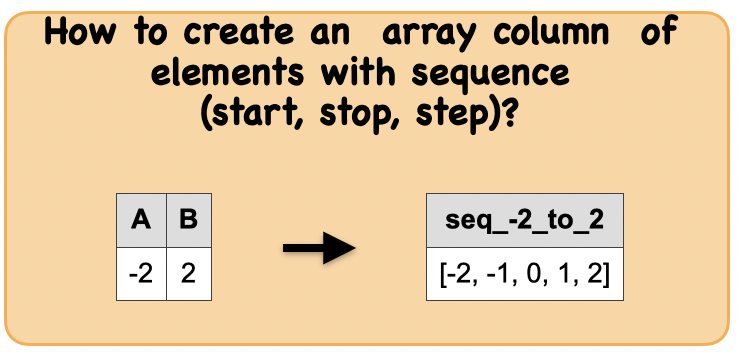
1o. How to create a array column containing elements with sequence(start, stop, step)?¶
Syntax
pyspark.sql.functions.sequence(start, stop, step=None)
Generate a sequence of integers from start to stop, incrementing by step. If step is not set, incrementing by 1 if start is less than or equal to stop, otherwise -1.
‘’’
Input: Spark data frame
df = spark.createDataFrame([(-2, 2)], ('A', 'B'))
df.show()
+---+---+
| A| B|
+---+---+
| -2| 2|
+---+---+
Output : Spark data frame with an array sequence
from pyspark.sql.functions import sequence
df_seq = df.select(sequence('A', 'B').alias('seq'))
df_seq.show()
+-----------------+
| seq|
+-----------------+
|[-2, -1, 0, 1, 2]|
+-----------------+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_seq.toPandas())
Input Output
| A | B |
|---|---|
| -2 | 2 |
| seq |
|---|
| [-2, -1, 0, 1, 2] |
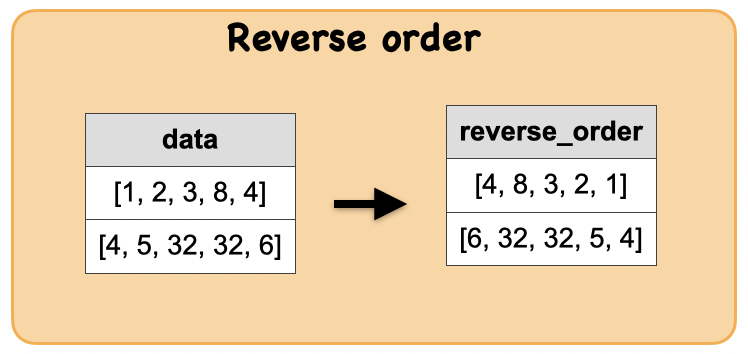
1p. How to reverse the order(not reverse sort) of an array in a column ?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.map_from_arrays(col1, col2)
Creates a new map from two arrays.
Parameters
col1 – name of column containing a set of keys. All elements should not be null
col2 – name of column containing a set of values
‘’’
Input: Spark data frame with an array column
df_arr = spark.createDataFrame([([1, 2, 3, 8, 4],), ([4, 5, 32, 32, 6],)], ['data'])
df_arr.show()
+-----------------+
| data|
+-----------------+
| [1, 2, 3, 8, 4]|
|[4, 5, 32, 32, 6]|
+-----------------+
Output : Spark data frame with a reverse ordered array column
from pyspark.sql.functions import reverse
df_rev = df_arr.select(reverse(df_arr.data).alias('reverse_order'))
df_rev.show(truncate=False)
+-----------------+
|reverse_order |
+-----------------+
|[4, 8, 3, 2, 1] |
|[6, 32, 32, 5, 4]|
+-----------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_arr.toPandas(),df_rev.toPandas())
Input Output
| data |
|---|
| [1, 2, 3, 8, 4] |
| [4, 5, 32, 32, 6] |
| reverse_order |
|---|
| [4, 8, 3, 2, 1] |
| [6, 32, 32, 5, 4] |
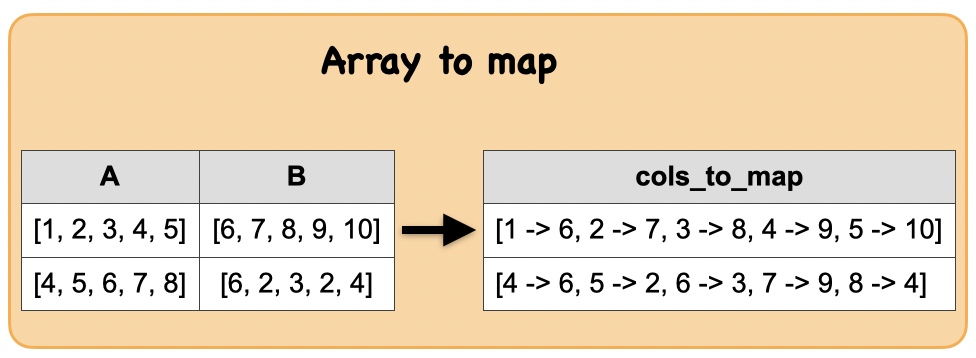
1q. How to combine two array columns into a map column?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.map_from_arrays(col1, col2)
Creates a new map from two arrays.
Parameters
col1 – name of column containing a set of keys. All elements should not be null
col2 – name of column containing a set of values
‘’’
Input: Spark data frame with 2 array columns
df_arrm = spark.createDataFrame([([1, 2, 3, 4, 5],[6, 7, 8, 9, 10]), ([4, 5, 6, 7, 8],[6, 2, 3, 9, 4])], ['A','B'])
df_arrm.show()
+---------------+----------------+
| A| B|
+---------------+----------------+
|[1, 2, 3, 4, 5]|[6, 7, 8, 9, 10]|
|[4, 5, 6, 7, 8]| [6, 2, 3, 9, 4]|
+---------------+----------------+
Output : Spark data frame with a map column
from pyspark.sql.functions import map_from_arrays
df_map = df_arrm.select(map_from_arrays(df_arrm.A, df_arrm.B).alias('map'))
df_map.show(truncate=False)
+-----------------------------------------+
|map |
+-----------------------------------------+
|[1 -> 6, 2 -> 7, 3 -> 8, 4 -> 9, 5 -> 10]|
|[4 -> 6, 5 -> 2, 6 -> 3, 7 -> 9, 8 -> 4] |
+-----------------------------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_arrm.toPandas(),df_map.toPandas())
Input Output
| A | B |
|---|---|
| [1, 2, 3, 4, 5] | [6, 7, 8, 9, 10] |
| [4, 5, 6, 7, 8] | [6, 2, 3, 9, 4] |
| map |
|---|
| {1: 6, 2: 7, 3: 8, 4: 9, 5: 10} |
| {8: 4, 4: 6, 5: 2, 6: 3, 7: 9} |
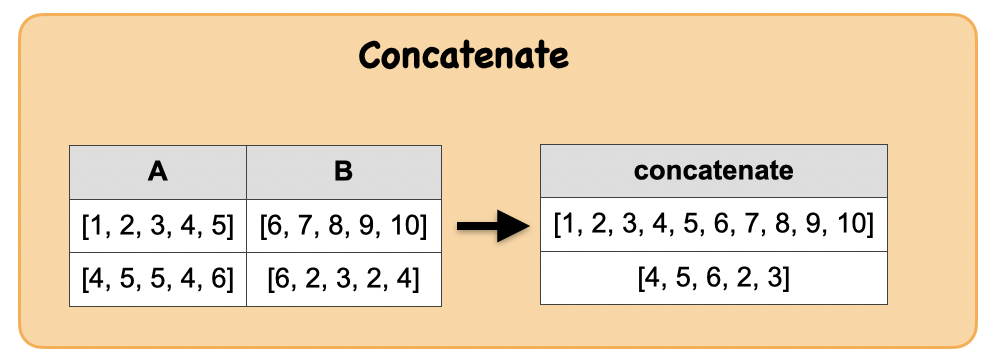
1r. How to concatenate the elements of an array in a column?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.concat(*cols)
Concatenates multiple input columns together into a single column. The function works with strings, binary and compatible array columns.
‘’’
Input: Spark data frame with a map column
df_arr1 = spark.createDataFrame([([1, 2, 3, 4, 5],[6, 7, 8, 9, 10]), ([4, 5, 6, 7, 8],[6, 2, 3, 9, 4])], ['A','B'])
df_arr1.show()
+---------------+----------------+
| A| B|
+---------------+----------------+
|[1, 2, 3, 4, 5]|[6, 7, 8, 9, 10]|
|[4, 5, 6, 7, 8]| [6, 2, 3, 9, 4]|
+---------------+----------------+
Output : Spark data frame with a date column
from pyspark.sql.functions import concat
df_con = df_arr1.select(concat(df_arr1.A, df_arr1.B).alias("concatenate"))
df_con.show(2,False)
+-------------------------------+
|concatenate |
+-------------------------------+
|[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]|
|[4, 5, 6, 7, 8, 6, 2, 3, 9, 4] |
+-------------------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_arr1.toPandas(),df_con.toPandas())
Input Output
| A | B |
|---|---|
| [1, 2, 3, 4, 5] | [6, 7, 8, 9, 10] |
| [4, 5, 6, 7, 8] | [6, 2, 3, 9, 4] |
| concatenate |
|---|
| [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
| [4, 5, 6, 7, 8, 6, 2, 3, 9, 4] |
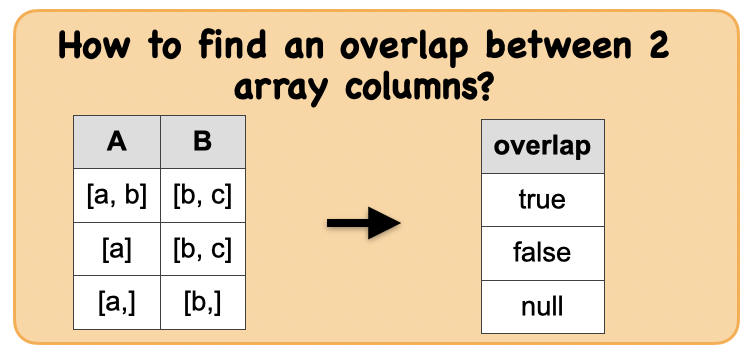
1s. How to find overlap between 2 array columns?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.arrays_overlap(a1, a2)
Collection function: returns true if the arrays contain any common non-null element; if not, returns null if both the arrays are non-empty and any of them contains a null element; returns false otherwise
‘’’
Input: Spark data frame with array columns
df_over = spark.createDataFrame([(["a", "b"], ["b", "c"],), (["a"], ["b", "c"],),(["a", None], ["b", None],) ], ['A', 'B'])
df_over.show()
+------+------+
| A| B|
+------+------+
|[a, b]|[b, c]|
| [a]|[b, c]|
| [a,]| [b,]|
+------+------+
Output : Spark data frame
from pyspark.sql.functions import arrays_overlap
df_overlap = df_over.select(arrays_overlap(df_over.A, df_over.B).alias("overlap"))
df_overlap.show()
+-------+
|overlap|
+-------+
| true|
| false|
| null|
+-------+
Summary:
print("Input ", "Output")
display_side_by_side(df_over.toPandas(),df_overlap.toPandas())
Input Output
| A | B |
|---|---|
| [a, b] | [b, c] |
| [a] | [b, c] |
| [a, None] | [b, None] |
| overlap |
|---|
| True |
| False |
| None |
1t. How to flatten a column containing nested arrays?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.flatten(col)
creates a single array from an array of arrays. If a structure of nested arrays is deeper than two levels, only one level of nesting is removed.
‘’’
Input: Spark data frame with nested array column
df4 = spark.createDataFrame([([[1, 2, 3, 8, 4],[6,8, 10]],), ([[4, 5, 32, 32, 6]],)], ['data'])
df4.show(truncate=False)
+-----------------------------+
|data |
+-----------------------------+
|[[1, 2, 3, 8, 4], [6, 8, 10]]|
|[[4, 5, 32, 32, 6]] |
+-----------------------------+
Output : Spark data frame with a flattended array column
from pyspark.sql.functions import flatten
df_flat = df4.select(flatten(df4.data).alias('flatten'))
df_flat.show(truncate=False)
+-------------------------+
|flatten |
+-------------------------+
|[1, 2, 3, 8, 4, 6, 8, 10]|
|[4, 5, 32, 32, 6] |
+-------------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df4.toPandas(),df_flat.toPandas())
Input Output
| data |
|---|
| [[1, 2, 3, 8, 4], [6, 8, 10]] |
| [[4, 5, 32, 32, 6]] |
| flatten |
|---|
| [1, 2, 3, 8, 4, 6, 8, 10] |
| [4, 5, 32, 32, 6] |
1u. How to concatenate the elements of an array in a column?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.array_join(col, delimiter, null_replacement=None)
Concatenates the elements of column using the delimiter. Null values are replaced with null_replacement if set, otherwise they are ignored.
‘’’
Input: Spark data frame with an array column
df_a1 = spark.createDataFrame([([1, 2, 3, 4, 5],), ([4, 5, None, 4, 6],)], ['A'])
df_a1.show()
+---------------+
| A|
+---------------+
|[1, 2, 3, 4, 5]|
| [4, 5,, 4, 6]|
+---------------+
Output : Spark data frame with a concatenated array element column
from pyspark.sql.functions import array_join
df_j1 = df_a1.select(array_join(df_a1.A,',').alias("array_join"))
df_j1.show()
+----------+
|array_join|
+----------+
| 1,2,3,4,5|
| 4,5,4,6|
+----------+
df_j2 = df_a1.select(array_join(df_a1.A,',', null_replacement="NA").alias("array_join"))
df_j2.show()
+----------+
|array_join|
+----------+
| 1,2,3,4,5|
|4,5,NA,4,6|
+----------+
Summary:
print("Input ", "Output")
display_side_by_side(df_a1.toPandas(),df_j1.toPandas(), df_j2.toPandas())
Input Output
| A |
|---|
| [1, 2, 3, 4, 5] |
| [4, 5, None, 4, 6] |
| array_join |
|---|
| 1,2,3,4,5 |
| 4,5,4,6 |
| array_join |
|---|
| 1,2,3,4,5 |
| 4,5,NA,4,6 |
1v. How to zip 2 array columns ?¶
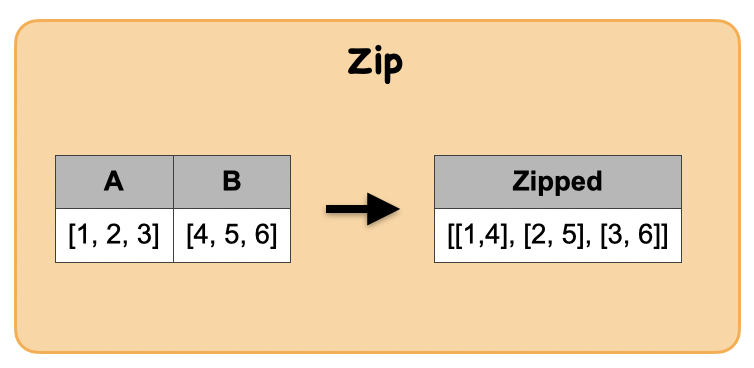
Lets first understand the syntax
Syntax
pyspark.sql.functions.arrays_zip(*cols)
Collection function: Returns a merged array of structs in which the N-th struct contains all N-th values of input arrays.
Parameters cols – columns of arrays to be merged.
‘’’
Input: Spark data frame with an array column
dfz = spark.createDataFrame([(([1, 2, 3], [4, 5, 6]))], ['A', 'B'])
dfz.show()
+---------+---------+
| A| B|
+---------+---------+
|[1, 2, 3]|[4, 5, 6]|
+---------+---------+
Output : Spark data frame with a zipped array column
from pyspark.sql.functions import arrays_zip
df_zip = dfz.select(arrays_zip(dfz.A, dfz.B).alias('zipped'))
df_zip.show(truncate=False)
+------------------------+
|zipped |
+------------------------+
|[[1, 4], [2, 5], [3, 6]]|
+------------------------+
Summary:
print("Input ", "Output")
display_side_by_side(dfz.toPandas(),df_zip.toPandas())
Input Output
| A | B |
|---|---|
| [1, 2, 3] | [4, 5, 6] |
| zipped |
|---|
| [(1, 4), (2, 5), (3, 6)] |