

Chapter 7 : Date Columns¶
Chapter Learning Objectives¶
Various data operations on columns containing date strings, date and timestamps.
Chapter Outline¶
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
from IPython.display import display_html
import pandas as pd
import numpy as np
def display_side_by_side(*args):
html_str=''
for df in args:
html_str+=df.to_html(index=False)
html_str+= "\xa0\xa0\xa0"*10
display_html(html_str.replace('table','table style="display:inline"'),raw=True)
space = "\xa0" * 10
import panel as pn
css = """
div.special_table + table, th, td {
border: 3px solid orange;
}
"""
pn.extension(raw_css=[css])
#<div class="special_table"></div>
Chapter Outline - Gallery¶
Timezone format conversions¶
click on |
any image |
|---|---|
|
|
|
|
|
|
|
Addition and subtraction on date columns ¶
click on |
any image |
|---|---|
|
|
|
|
|
Extract year, month, date, hour, minute, second, day, weekday, week/quarter of year from a datetime column ¶
1a. How to convert string timestamp to date format?¶
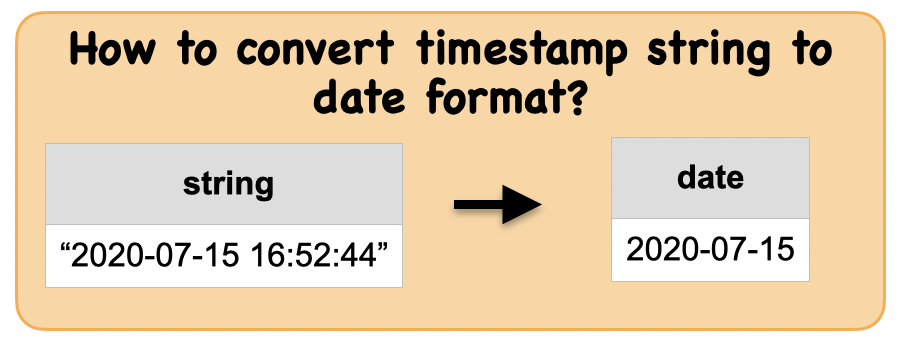
Lets first understand the syntax
Syntax
pyspark.sql.functions.to_date(col, format=None)
Converts a Column into pyspark.sql.types.DateType using the optionally specified format.
Specify formats according to datetime pattern. By default, it follows casting rules to pyspark.sql.types.DateType if the format is omitted.
Equivalent to col.cast(“date”).
‘’’
Input: Spark data frame with a column having a string of timestamp
df_str = spark.createDataFrame([('2020-07-15 16:52:44',)], ['string_timestamp'])
df_str.show()
+-------------------+
| string_timestamp|
+-------------------+
|2020-07-15 16:52:44|
+-------------------+
Output : Spark data frame with a date column
from pyspark.sql.functions import to_date
df_date = df_str.select(to_date(df_str.string_timestamp).alias('date'))
df_date.show()
+----------+
| date|
+----------+
|2020-07-15|
+----------+
Summary:
print("Input ", "Output")
display_side_by_side(df_str.toPandas(),df_date.toPandas())
Input Output
| string_timestamp |
|---|
| 2020-07-15 16:52:44 |
| date |
|---|
| 2020-07-15 |
1b. How to convert a string timestamp to datetime format?¶
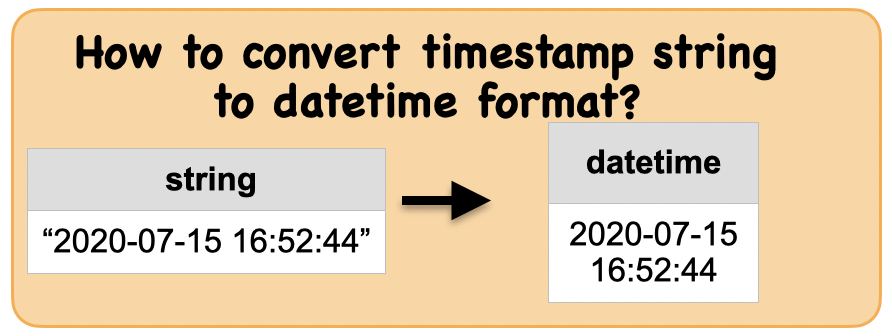
Lets first understand the syntax
Syntax
pyspark.sql.functions.to_timestamp(col, format=None)
Converts a Column into pyspark.sql.types.TimestampType using the optionally specified format.
Specify formats according to datetime pattern. By default, it follows casting rules to pyspark.sql.types.TimestampType if the format is omitted.
Equivalent to col.cast(“timestamp”). ‘’’
Input: Spark data frame with a column having a string of timestamp
df_string = spark.createDataFrame([('2020-07-15 16:52:44',)], ['string_timestamp'])
df_string.show()
+-------------------+
| string_timestamp|
+-------------------+
|2020-07-15 16:52:44|
+-------------------+
Output : Spark data frame with a timestamp column
from pyspark.sql.functions import to_timestamp
df_datetime = df_string.select(to_timestamp(df_string.string_timestamp).alias('datetime'))
df_datetime.show()
+-------------------+
| datetime|
+-------------------+
|2020-07-15 16:52:44|
+-------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_string.toPandas(),df_datetime.toPandas())
Input Output
| string_timestamp |
|---|
| 2020-07-15 16:52:44 |
| datetime |
|---|
| 2020-07-15 16:52:44 |
1c. How to convert unix timestamp to a string timestamp?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.from_unixtime(timestamp, format=’yyyy-MM-dd HH:mm:ss’)
Converts the number of seconds from unix epoch (1970-01-01 00:00:00 UTC) to a string representing the timestamp of that moment in the current system time zone in the given format.
‘’’
Input: Spark data frame with a number column representing unix time
df_unix = spark.createDataFrame([(1594846364,)], ['unix_time'])
df_unix.show()
+----------+
| unix_time|
+----------+
|1594846364|
+----------+
Output : Spark data frame with a column with a sliced string
from pyspark.sql.functions import from_unixtime
df_time = df_unix.select(from_unixtime(df_unix.unix_time).alias("timestamp_string"))
df_time.show(truncate=False)
+-------------------+
|timestamp_string |
+-------------------+
|2020-07-15 16:52:44|
+-------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_unix.toPandas(),df_time.toPandas())
Input Output
| unix_time |
|---|
| 1594846364 |
| timestamp_string |
|---|
| 2020-07-15 16:52:44 |
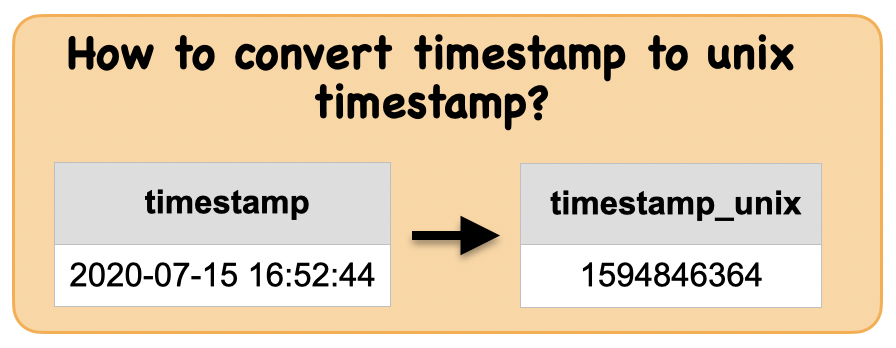
1d. How to convert a timestamp to unix timestamp?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.unix_timestamp(timestamp=None, format=’yyyy-MM-dd HH:mm:ss’)
Convert time string with given pattern (‘yyyy-MM-dd HH:mm:ss’, by default) to Unix time stamp (in seconds), using the default timezone and the default locale, return null if fail.
‘’’
Input: Spark data frame consisting of a timestamp column in UTC
from pyspark.sql.functions import current_timestamp
df = spark.createDataFrame([(),],)
df = df.select(current_timestamp().alias("timestamp"))
df.show(truncate=False)
+----------------------+
|timestamp |
+----------------------+
|2021-03-13 21:42:38.01|
+----------------------+
Output : Spark data frame consisting of a unix timestamp column
from pyspark.sql.functions import unix_timestamp
df_unix = df.select(unix_timestamp(df.timestamp).alias("unixtimestamp"))
df_unix.show(truncate=False)
+-------------+
|unixtimestamp|
+-------------+
|1615689758 |
+-------------+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_unix.toPandas())
Input Output
| timestamp |
|---|
| 2021-03-13 21:42:38.659 |
| unixtimestamp |
|---|
| 1615689758 |
1e. How to convert timestamp in UTC timezone to a given time zone?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.from_utc_timestamp(timestamp, tz)
This is a common function for databases supporting TIMESTAMP WITHOUT TIMEZONE. This function takes a timestamp which is timezone-agnostic, and interprets it as a timestamp in UTC, and renders that timestamp as a timestamp in the given time zone.
However, timestamp in Spark represents number of microseconds from the Unix epoch, which is not timezone-agnostic. So in Spark this function just shift the timestamp value from UTC timezone to the given timezone.
This function may return confusing result if the input is a string with timezone, e.g. ‘2018-03-13T06:18:23+00:00’. The reason is that, Spark firstly cast the string to timestamp according to the timezone in the string, and finally display the result by converting the timestamp to string according to the session local timezone.
Parameters
timestamp – the column that contains timestamps
tz – A string detailing the time zone ID that the input should be adjusted to. It should be in the format of
either region-based zone IDs or zone offsets. Region IDs must have the form ‘area/city’, such as ‘America/Los_Angeles’. Zone offsets must be in the format ‘(+|-)HH:mm’, for example ‘-08:00’ or ‘+01:00’. Also ‘UTC’ and ‘Z’ are supported as aliases of ‘+00:00’. Other short names are not recommended to use because they can be ambiguous. ‘’’
Input: Spark data frame consisting of a timestamp column in UTC time zone
# Please note that below timestamp is in UTC.
df_utc = spark.createDataFrame([(),],)
df_utc = df_utc.select(current_timestamp().alias("timestamp_UTC"))
df_utc.show(truncate=False)
+-----------------------+
|timestamp_UTC |
+-----------------------+
|2021-03-13 21:42:38.959|
+-----------------------+
Output : Spark data frame consisting of a timestamp column in different timezone
from pyspark.sql.functions import from_utc_timestamp
df_tz = df_utc.select(from_utc_timestamp(df_utc.timestamp_UTC,'UTC-4').alias("timestamp in local TZ"))
df_tz.show(truncate=False)
+-----------------------+
|timestamp in local TZ |
+-----------------------+
|2021-03-13 17:42:39.213|
+-----------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_utc.toPandas(),df_tz.toPandas())
Input Output
| timestamp_UTC |
|---|
| 2021-03-13 21:42:39.362 |
| timestamp in local TZ |
|---|
| 2021-03-13 17:42:39.487 |
1f. How to convert from a given time zone to UTC timestamps?¶

Lets first understand the syntax
{admonition} Syntax pyspark.sql.functions.to_utc_timestamp(timestamp, tz)
This is a common function for databases supporting TIMESTAMP WITHOUT TIMEZONE. This function takes a timestamp which is timezone-agnostic, and interprets it as a timestamp in the given timezone, and renders that timestamp as a timestamp in UTC.
However, timestamp in Spark represents number of microseconds from the Unix epoch, which is not timezone-agnostic. So in Spark this function just shift the timestamp value from the given timezone to UTC timezone.
This function may return confusing result if the input is a string with timezone, e.g. ‘2018-03-13T06:18:23+00:00’. The reason is that, Spark firstly cast the string to timestamp according to the timezone in the string, and finally display the result by converting the timestamp to string according to the session local timezone.
Parameters
timestamp – the column that contains timestamps
tz – A string detailing the time zone ID that the input should be adjusted to. It should be in the format of either region-based zone IDs or zone offsets. Region IDs must have the form ‘area/city’, such as ‘America/Los_Angeles’. Zone offsets must be in the format ‘(+|-)HH:mm’, for example ‘-08:00’ or ‘+01:00’. Also ‘UTC’ and ‘Z’ are supported as aliases of ‘+00:00’. Other short names are not recommended to use because they can be ambiguous.
Input: Spark data frame consisting of a timestamp column in UTC time zone
# Please note that local time zone is EST.
df_est = spark.createDataFrame([(),],)
df_est = df.select(current_timestamp().alias("timestamp"))
df_est.show(truncate=False)
+-----------------------+
|timestamp |
+-----------------------+
|2021-03-13 21:42:39.695|
+-----------------------+
Output : Spark data frame consisting of a timestamp column in different timezone
from pyspark.sql.functions import to_utc_timestamp
df_utc = df_est.select(to_utc_timestamp(df_est.timestamp,'GMT-4').alias("timestamp in UTC"))
df_utc.show(truncate=False)
+-----------------------+
|timestamp in UTC |
+-----------------------+
|2021-03-14 01:42:40.042|
+-----------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_est.toPandas(),df_utc.toPandas())
Input Output
| timestamp |
|---|
| 2021-03-13 21:42:40.310 |
| timestamp in UTC |
|---|
| 2021-03-14 01:42:40.500 |
1g. How to convert the date format?¶
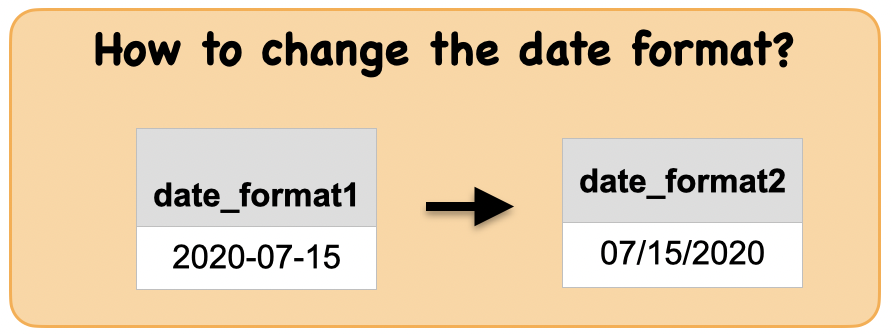
Lets first understand the syntax
Syntax
pyspark.sql.functions.date_format(date, format)
Converts a date/timestamp/string to a value of string in the format specified by the date format given by the second argument.
A pattern could be for instance dd.MM.yyyy and could return a string like ‘18.03.1993’. All pattern letters of datetime pattern. can be used.
Parameters:
col : column ‘’’
Input: Spark data frame with a string date column
df_format1 = spark.createDataFrame([('2020-07-15',)], ['date_format1'])
df_format1.show()
+------------+
|date_format1|
+------------+
| 2020-07-15|
+------------+
Output : Spark data frame with a formatted date
from pyspark.sql.functions import date_format
df_format2 = df_format1.select(date_format('date_format1', 'MM/dd/yyy').alias('date_format2'))
df_format2.show()
+------------+
|date_format2|
+------------+
| 07/15/2020|
+------------+
Summary:
print("input ", "output")
display_side_by_side(df_format1.toPandas(),df_format2.toPandas())
input output
| date_format1 |
|---|
| 2020-07-15 |
| date_format2 |
|---|
| 07/15/2020 |
2a. How to find no of days between 2 dates?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.datediff(end, start)
Returns the number of days from start to end.
‘’’
Input: Spark data frame consisting of date columns
df_dates = spark.createDataFrame([('2020-07-15','2020-06-10')], ['date1', 'date2'])
df_dates.show()
+----------+----------+
| date1| date2|
+----------+----------+
|2020-07-15|2020-06-10|
+----------+----------+
Output : Spark data frame with a days diff
from pyspark.sql.functions import datediff
df_diff = df_dates.select(datediff(df_dates.date1,df_dates.date2).alias('diff'))
df_diff.show()
+----+
|diff|
+----+
| 35|
+----+
Summary:
print("Input ", "Output")
display_side_by_side(df_dates.toPandas(),df_diff.toPandas())
Input Output
| date1 | date2 |
|---|---|
| 2020-07-15 | 2020-06-10 |
| diff |
|---|
| 35 |
2b. How to find no of months between 2 dates?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.months_between(date1, date2, roundOff=True)
Returns number of months between dates date1 and date2. If date1 is later than date2, then the result is positive. If date1 and date2 are on the same day of month, or both are the last day of month, returns an integer (time of day will be ignored). The result is rounded off to 8 digits unless roundOff is set to False.
‘’’
Input: Spark data frame with date columns
df_month = spark.createDataFrame([('2020-07-15 11:32:00', '2020-01-30')], ['date1', 'date2'])
df_month.show()
+-------------------+----------+
| date1| date2|
+-------------------+----------+
|2020-07-15 11:32:00|2020-01-30|
+-------------------+----------+
Output : Spark data frame with months between 2 dates
from pyspark.sql.functions import months_between
df_month_diff = df_month.select(months_between(df_month.date1, df_month.date2))
df_month_diff.show()
+----------------------------------+
|months_between(date1, date2, true)|
+----------------------------------+
| 5.53163082|
+----------------------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_month.toPandas(),df_month_diff.toPandas())
Input Output
| date1 | date2 |
|---|---|
| 2020-07-15 11:32:00 | 2020-01-30 |
| months_between(date1, date2, true) |
|---|
| 5.531631 |
2c. How to add no of days to a date?¶
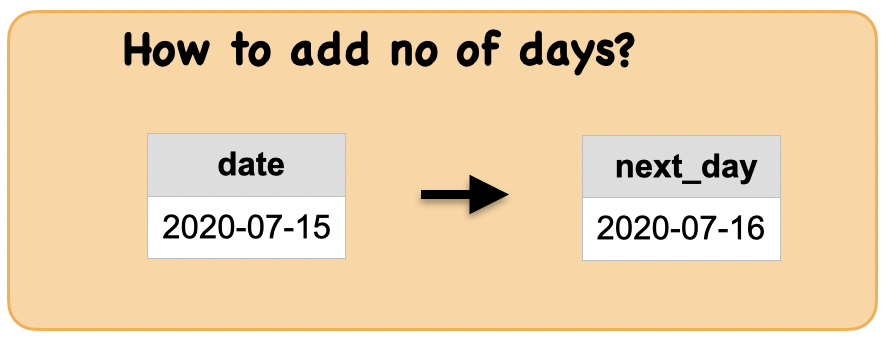
Lets first understand the syntax
Syntax
pyspark.sql.functions.date_add(start, days)
Returns the date that is days days after start ‘’’
Input: Spark data frame with a string date column
df_today = spark.createDataFrame([('2020-07-15',)], ['date'])
df_today.show()
+----------+
| date|
+----------+
|2020-07-15|
+----------+
Output : Spark data frame with a new date
from pyspark.sql.functions import date_add
df_tomo = df_today.select(date_add(df_today.date, 1).alias('next_day'))
df_tomo.show()
+----------+
| next_day|
+----------+
|2020-07-16|
+----------+
Summary:
print("input ", "output")
display_side_by_side(df_today.toPandas(),df_tomo.toPandas())
input output
| date |
|---|
| 2020-07-15 |
| next_day |
|---|
| 2020-07-16 |
2d. How to subtract no of days from a date?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.date_sub(start, days)
Returns the date that is days days before start
‘’’
Input: Spark data frame with a date column
df_date = spark.createDataFrame([('2020-07-15',)], ['date'])
df_date.show()
+----------+
| date|
+----------+
|2020-07-15|
+----------+
Output : Spark data frame with a date column
from pyspark.sql.functions import date_sub
df_sub = df_date.select(date_sub(df_date.date, 1).alias('yesterday'))
df_sub.show()
+----------+
| yesterday|
+----------+
|2020-07-14|
+----------+
Summary:
print("Input ", "Output")
display_side_by_side(df_date.toPandas(),df_sub.toPandas())
Input Output
| date |
|---|
| 2020-07-15 |
| yesterday |
|---|
| 2020-07-14 |
2e. How to add no of months to a date?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.add_months(start, months)[source]
Returns the date that is months months after start ‘’’
Input: Spark data frame consisting of a date column
df = spark.createDataFrame([('2020-07-15',)], ['date'])
df.show()
+----------+
| date|
+----------+
|2020-07-15|
+----------+
Output : Spark data frame consisting of a date column
from pyspark.sql.functions import add_months
df1 = df.select(add_months(df.date, 1).alias('next_month'))
df1.show()
+----------+
|next_month|
+----------+
|2020-08-15|
+----------+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df1.toPandas())
Input Output
| date |
|---|
| 2020-07-15 |
| next_month |
|---|
| 2020-08-15 |
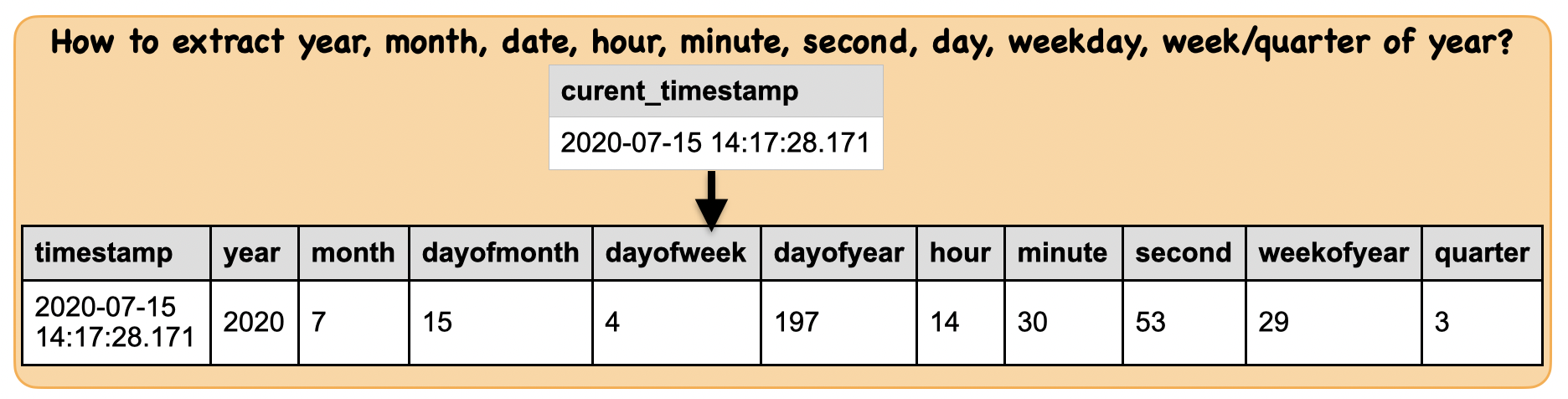
How to extract year, month, date, hour, minute, second, day, weekday, week/quarter of year from a datetime column?¶
Input: Spark data frame consisting of a datetime column
df = spark.createDataFrame([(),],)
df = df.select(current_timestamp().alias("timestamp"))
df.show(truncate=False)
+-----------------------+
|timestamp |
+-----------------------+
|2021-03-13 21:42:44.661|
+-----------------------+
Output : Spark data frame consisting of many columns
from pyspark.sql.functions import year, month, dayofmonth, dayofweek, dayofyear, hour, minute, second, weekofyear, quarter
df2 = df.select(df.timestamp,year(df.timestamp).alias("year"),
month(df.timestamp).alias("month"), dayofmonth(df.timestamp).alias("dayofmonth"),
dayofweek(df.timestamp).alias("dayofweek"), dayofyear(df.timestamp).alias("dayofyear"),
hour(df.timestamp).alias("hour"), minute(df.timestamp).alias("minute"),
second(df.timestamp).alias("second"), weekofyear(df.timestamp).alias("weekofyear"),
quarter(df.timestamp).alias("quarter"))
df2.show(truncate=False)
+-----------------------+----+-----+----------+---------+---------+----+------+------+----------+-------+
|timestamp |year|month|dayofmonth|dayofweek|dayofyear|hour|minute|second|weekofyear|quarter|
+-----------------------+----+-----+----------+---------+---------+----+------+------+----------+-------+
|2021-03-13 21:42:44.997|2021|3 |13 |7 |72 |21 |42 |44 |10 |1 |
+-----------------------+----+-----+----------+---------+---------+----+------+------+----------+-------+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df2.toPandas())
Input Output
| timestamp |
|---|
| 2021-03-13 21:42:45.180 |
| timestamp | year | month | dayofmonth | dayofweek | dayofyear | hour | minute | second | weekofyear | quarter |
|---|---|---|---|---|---|---|---|---|---|---|
| 2021-03-13 21:42:45.282 | 2021 | 3 | 13 | 7 | 72 | 21 | 42 | 45 | 10 | 1 |