

Chapter 5 : String Columns¶
Chapter Learning Objectives¶
Various data operations on columns containing string.
Chapter Outline¶
# import panel as pn
# css = """
# div.special_table + table, th, td {
# border: 3px solid orange;
# }
# """
# pn.extension(raw_css=[css])
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
from IPython.display import display_html
import pandas as pd
import numpy as np
def display_side_by_side(*args):
html_str=''
for df in args:
html_str+=df.to_html(index=False)
html_str+= "\xa0\xa0\xa0"*10
display_html(html_str.replace('table','table style="display:inline"'),raw=True)
space = "\xa0" * 10
1a. How to split a string?¶
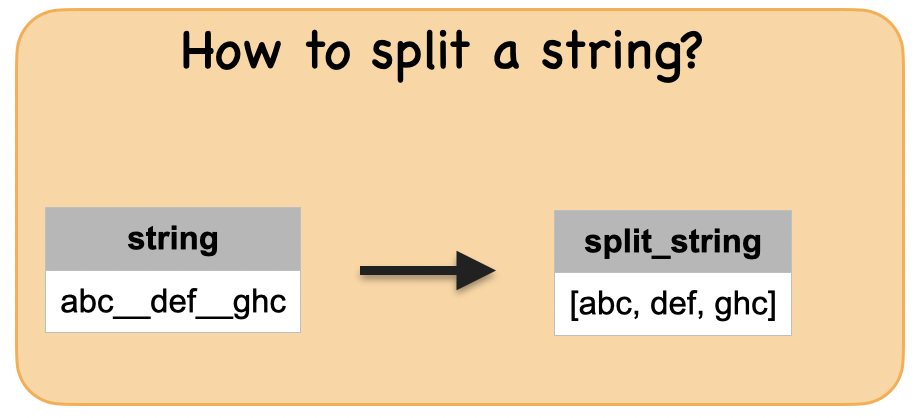
Lets first understand the syntax
Syntax
pyspark.sql.functions.split(str, pattern, limit=-1)
Splits str around matches of the given pattern.
Parameters:
str : a string expression to split
pattern : a string representing a regular expression. The regex string should be a Java regular expression.
limit : an integer which controls the number of times pattern is applied.
limit > 0: The resulting array’s length will not be more than limit, and the resulting array’s last entry will contain all input beyond the last matched pattern.
limit <= 0: pattern will be applied as many times as possible, and the resulting array can be of any size. ‘’’
Input: Spark data frame with a column having a string
df_string = spark.createDataFrame([('abc__def__ghc',)], ['string',])
df_string.show()
+-------------+
| string|
+-------------+
|abc__def__ghc|
+-------------+
Output : Spark data frame with a column with a split string
from pyspark.sql.functions import split
df_split = df_string.select(split(df_string.string,'__').alias('split_string'))
df_split.show()
+---------------+
| split_string|
+---------------+
|[abc, def, ghc]|
+---------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_string.toPandas(),df_split.toPandas())
Input Output
| string |
|---|
| abc__def__ghc |
| split_string |
|---|
| [abc, def, ghc] |
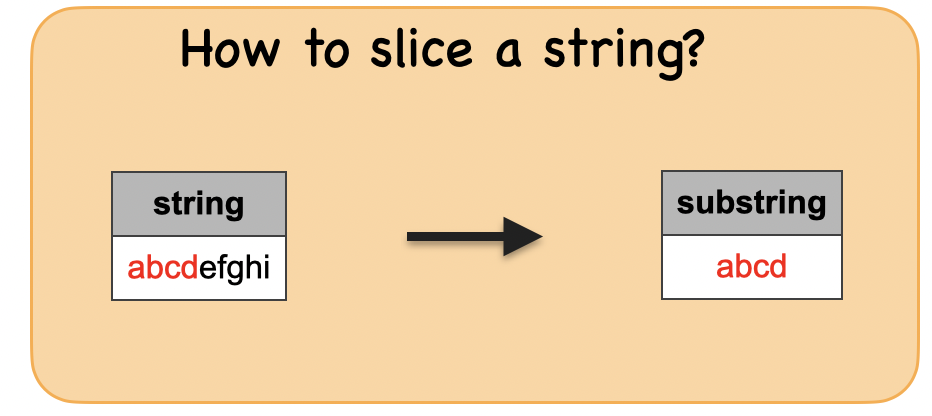
1b. How to slice a string?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.slice(x, start, length)
Collection function: returns an array containing all the elements in x from index start (array indices start at 1, or from the end if start is negative) with the specified length.
Parameters:
x : the array to be sliced
start : the starting index
length : the length of the slice ‘’’
Input: Spark data frame with a column having a string
df_string = spark.createDataFrame([('abcdefghi',)], ['string',])
df_string.show()
+---------+
| string|
+---------+
|abcdefghi|
+---------+
Output : Spark data frame with a column with a sliced string
from pyspark.sql.functions import substring
df_sub = df_string.select(substring(df_string.string,1,4).alias('substring'))
df_sub.show()
+---------+
|substring|
+---------+
| abcd|
+---------+
Summary:
print("Input ", "Output")
display_side_by_side(df_string.toPandas(),df_sub.toPandas())
Input Output
| string |
|---|
| abcdefghi |
| substring |
|---|
| abcd |
1c. How to convert lowercase to uppercase?¶
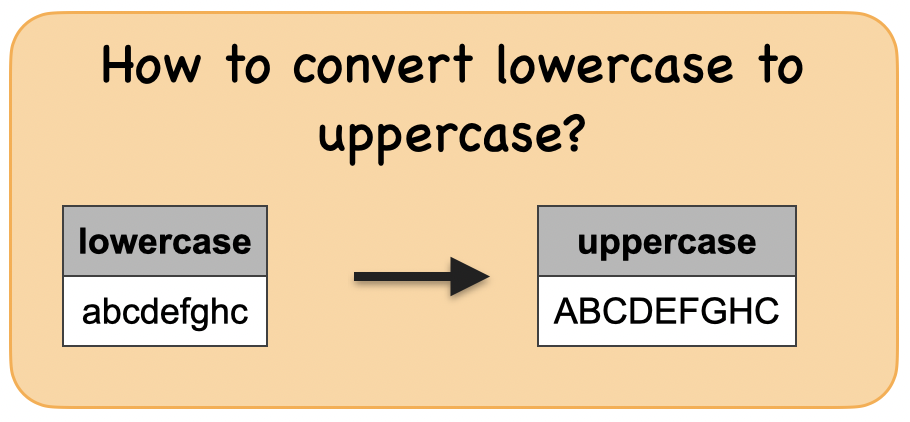
Lets first understand the syntax
Converts a string expression to upper case.
Syntax
pyspark.sql.functions.upper(col)
Converts a string expression to lower case.
Parameters:
col : column ‘’’
Input: Spark data frame with a column having a lowercase string
df_upper = spark.createDataFrame([('ABCDEFGHI',)], ['uppercase',])
df_upper.show()
+---------+
|uppercase|
+---------+
|ABCDEFGHI|
+---------+
Output : Spark data frame with a column having a uppercase string
from pyspark.sql.functions import lower
df_lower= df_upper.select(lower(df_upper.uppercase).alias('lowercase'))
df_lower.show()
+---------+
|lowercase|
+---------+
|abcdefghi|
+---------+
Summary:
print("input ", "output")
display_side_by_side(df_upper.toPandas(),df_lower.toPandas())
input output
| uppercase |
|---|
| ABCDEFGHI |
| lowercase |
|---|
| abcdefghi |
1d. How to convert uppercase to lowercase?¶
Lets first understand the syntax
Syntax
pyspark.sql.functions.lower(col)
Converts a string expression to lower case.
Parameters:
col : column ‘’’
Input: Spark data frame with a column having a string
df_string = spark.createDataFrame([('abcdefghc',)], ['lowercase',])
df_string.show()
+---------+
|lowercase|
+---------+
|abcdefghc|
+---------+
Output : Spark data frame with a column with a split string
from pyspark.sql.functions import upper
df_upper= df_string.select(upper(df_string.lowercase).alias('uppercase'))
df_upper.show()
+---------+
|uppercase|
+---------+
|ABCDEFGHC|
+---------+
Summary:
print("Input ", "Output")
display_side_by_side(df_string.toPandas(),df_upper.toPandas())
Input Output
| lowercase |
|---|
| abcdefghc |
| uppercase |
|---|
| ABCDEFGHC |
1e. How to extract a specific group matched by a Java regex?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.regexp_extract(str, pattern, idx)
Extract a specific group matched by a Java regex, from the specified string column. If the regex did not match, or the specified group did not match, an empty string is returned. ‘’’
Input: Spark data frame with a column having a string
df = spark.createDataFrame([('100-200',)], ['str'])
df.show()
+-------+
| str|
+-------+
|100-200|
+-------+
Output : Spark data frame with a column with a split string
from pyspark.sql.functions import regexp_extract
df_regex1 = df.select(regexp_extract('str', r'(\d+)-(\d+)', 1).alias('regex'))
df_regex1.show()
+-----+
|regex|
+-----+
| 100|
+-----+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_regex1.toPandas())
Input Output
| str |
|---|
| 100-200 |
| regex |
|---|
| 100 |
1f. How to replace a specific group matched by a Java regex?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.regexp_replace(str, pattern, replacement)
Replace all substrings of the specified string value that match regexp with rep. ‘’’
Input: Spark data frame with a column having a string
df = spark.createDataFrame([('100-200',)], ['string'])
df.show()
+-------+
| string|
+-------+
|100-200|
+-------+
Output : Spark data frame with a column with a regex
from pyspark.sql.functions import regexp_replace
df_regex2 = df.select(regexp_replace('string', r'(\d+)', '--').alias('replace'))
df_regex2.show()
+-------+
|replace|
+-------+
| -----|
+-------+
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_regex2.toPandas())
Input Output
| string |
|---|
| 100-200 |
| replace |
|---|
| ----- |