

Chapter 6 : Number Columns¶
Chapter Learning Objectives¶
Various data operations on columns containing numbers.
Chapter Outline¶
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
from IPython.display import display_html
import pandas as pd
import numpy as np
def display_side_by_side(*args):
html_str=''
for df in args:
html_str+=df.to_html(index=False)
html_str+= "\xa0\xa0\xa0"*10
display_html(html_str.replace('table','table style="display:inline"'),raw=True)
space = "\xa0" * 10
import panel as pn
css = """
div.special_table + table, th, td {
border: 3px solid orange;
}
"""
pn.extension(raw_css=[css])
1a. How to calculate the minimum value in a column?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.min(col)
Aggregate function: returns the minimum value of the expression in a group.
Parameters:
col : column
‘’’
Input: Spark data frame with a column having a string
df_min = spark.createDataFrame([(1,),(2,),(3,)],['data'])
df_min.show()
+----+
|data|
+----+
| 1|
| 2|
| 3|
+----+
Output : Spark data frame with a column with a split string
from pyspark.sql.functions import min
df_min.select(min(df_min.data)).first()[0]
1
Summary:
print("Input ", "Output")
display_side_by_side(df_min.toPandas(),df_min.select(min(df_min.data)).toPandas())
Input Output
| data |
|---|
| 1 |
| 2 |
| 3 |
| min(data) |
|---|
| 1 |
1b. How to calculate the maximum value in a column?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.max(col)
Aggregate function: returns the maximum value of the expression in a group
Parameters:
col : column ‘’’
Input: Spark data frame with a column having a string
df_max = spark.createDataFrame([(1,),(2,),(3,)],['data'])
df_max.show()
+----+
|data|
+----+
| 1|
| 2|
| 3|
+----+
Output : Spark data frame with a column with a split string
from pyspark.sql.functions import max
df_max.select(max(df_max.data)).first()[0]
3
Summary:
print("Input ", "Output")
display_side_by_side(df_max.toPandas(),df_max.select(max(df_max.data)).toPandas())
Input Output
| data |
|---|
| 1 |
| 2 |
| 3 |
| max(data) |
|---|
| 3 |
1c. How to calculate the sum of a column?¶
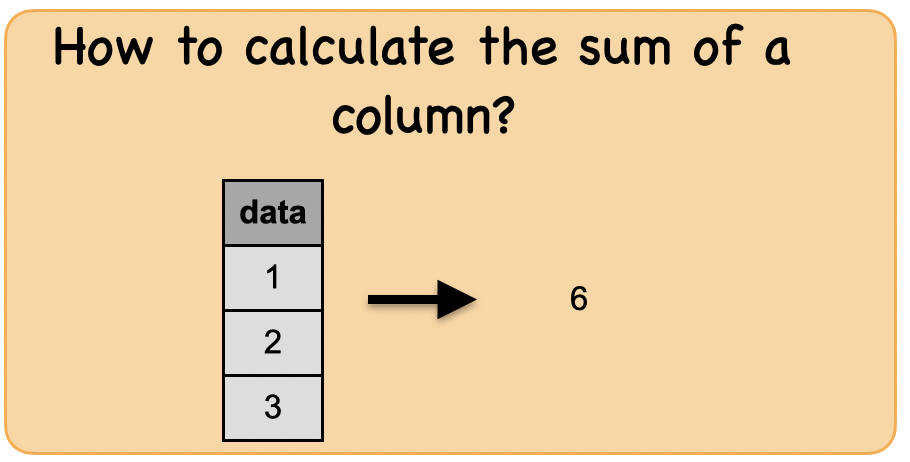
Lets first understand the syntax
Converts a string expression to upper case.
Syntax
pyspark.sql.functions.sum(col)
Aggregate function: returns the sum of all values in the expression.
Parameters:
col : column ‘’’
Input: Spark data frame with a column having a lowercase string
df_sum = spark.createDataFrame([(1,),(2,),(3,)],['data'])
df_sum.show()
+----+
|data|
+----+
| 1|
| 2|
| 3|
+----+
Output : Spark data frame with a column having a uppercase string
from pyspark.sql.functions import sum
df_sum.select(sum(df_sum.data)).first()[0]
6
Summary:
print("input ", "output")
display_side_by_side(df_sum.toPandas(),df_sum.select(sum(df_sum.data)).toPandas())
input output
| data |
|---|
| 1 |
| 2 |
| 3 |
| sum(data) |
|---|
| 6 |
1d. How to round values in a column?¶
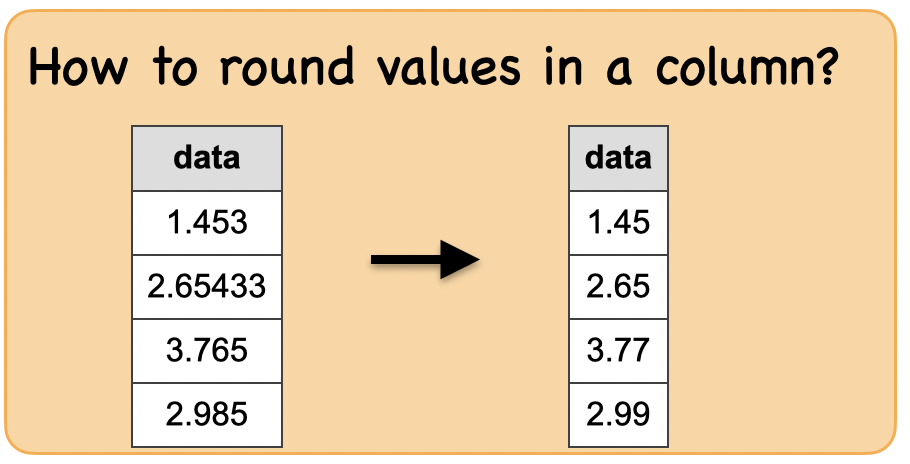
Lets first understand the syntax
Syntax
pyspark.sql.functions.round(col, scale=0)
Round the given value to scale decimal places using HALF_UP rounding mode if scale >= 0 or at integral part when scale < 0.
Parameters:
col : column ‘’’
Input: Spark data frame with a column having a string
df_round = spark.createDataFrame([(1.453,),(2.65433,),(3.765,),(2.985,)],['data'])
df_round.show()
+-------+
| data|
+-------+
| 1.453|
|2.65433|
| 3.765|
| 2.985|
+-------+
Output : Spark data frame with a column with a sliced string
from pyspark.sql.functions import round
df_round1 = df_round.select(round(df_round.data,2))
df_round1.show()
+--------------+
|round(data, 2)|
+--------------+
| 1.45|
| 2.65|
| 3.77|
| 2.99|
+--------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_round.toPandas(),df_round1.toPandas())
Input Output
| data |
|---|
| 1.45300 |
| 2.65433 |
| 3.76500 |
| 2.98500 |
| round(data, 2) |
|---|
| 1.45 |
| 2.65 |
| 3.77 |
| 2.99 |
1e. How to calculate the mean of a column?¶
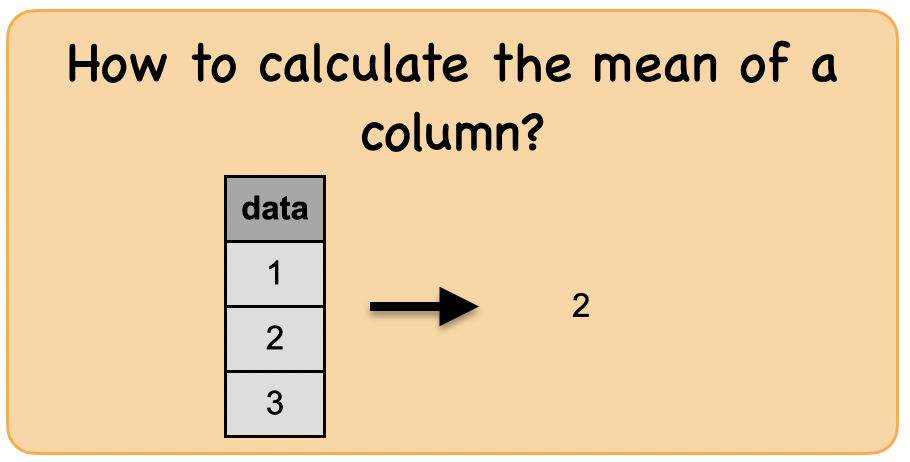
Lets first understand the syntax
Syntax
pyspark.sql.functions.mean(col)
Aggregate function: returns the average of the values in a group
Parameters:
col : column ‘’’
Input: Spark data frame with a column having a string
df_mean = spark.createDataFrame([(1,),(2,),(3,)],['data'])
df_mean.show()
+----+
|data|
+----+
| 1|
| 2|
| 3|
+----+
Output : Spark data frame with a column with a split string
from pyspark.sql.functions import mean
df_mean.select(mean(df_mean.data)).first()[0]
2.0
Summary:
print("Input ", "Output")
display_side_by_side(df_mean.toPandas(),df_mean.select(mean(df_mean.data)).toPandas())
Input Output
| data |
|---|
| 1 |
| 2 |
| 3 |
| avg(data) |
|---|
| 2.0 |
1f. How to calculate the standard deviation of a column?¶
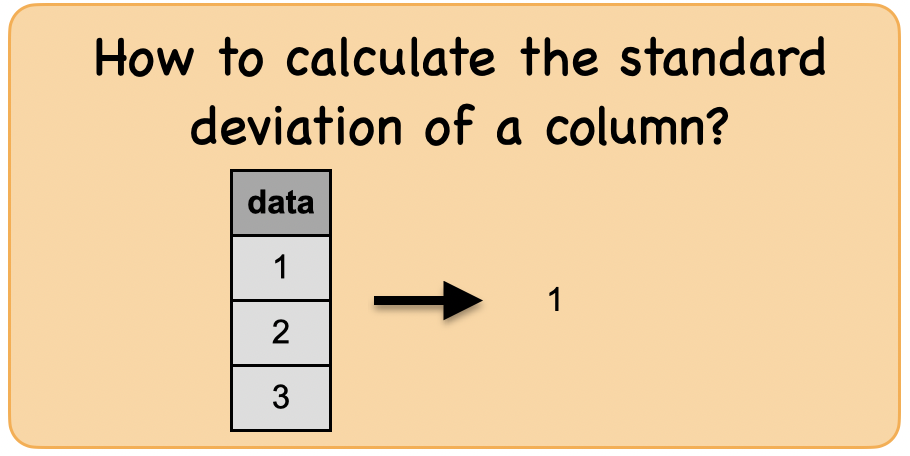
Lets first understand the syntax
Syntax
pyspark.sql.functions.stddev(col)
Aggregate function: alias for stddev_samp.
‘’’
Input: Spark data frame with a column having a string
df_stddev = spark.createDataFrame([(1,),(2,),(3,)],['data'])
df_stddev.show()
+----+
|data|
+----+
| 1|
| 2|
| 3|
+----+
Output : Spark data frame with a column with a regex
from pyspark.sql.functions import stddev
df_stddev.select(stddev(df_stddev.data)).first()[0]
1.0
Summary:
print("Input ", "Output")
display_side_by_side(df_stddev.toPandas(),df_stddev.select(stddev(df_stddev.data)).toPandas())
Input Output
| data |
|---|
| 1 |
| 2 |
| 3 |
| stddev_samp(data) |
|---|
| 1.0 |