

Chapter 11 : JSON Column¶
Chapter Learning Objectives¶
Various data operations on columns containing Json string.
Chapter Outline¶
1. How to deal with JSON string column?
1a. How to create a spark dataframe with a JSON string column ?
1b. How to infer a schema in DDL format from a JSON string column ?
1e. How to convert JSON string column into StructType column?
1g. How to convert JSON string column into ArrayType column?
1h. How to convert StructType/MapType/ArrayType column into JSON string?
1j. How to extract JSON objects based on list of field names?
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
from IPython.display import display_html
import pandas as pd
import numpy as np
def display_side_by_side(*args):
html_str=''
for df in args:
html_str+=df.to_html(index=False)
html_str+= "\xa0\xa0\xa0"*10
display_html(html_str.replace('table','table style="display:inline"'),raw=True)
space = "\xa0" * 10
import panel as pn
css = """
div.special_table + table, th, td {
border: 3px solid orange;
}
"""
pn.extension(raw_css=[css])

1a. How to create a spark dataframe with a JSON string column ?¶
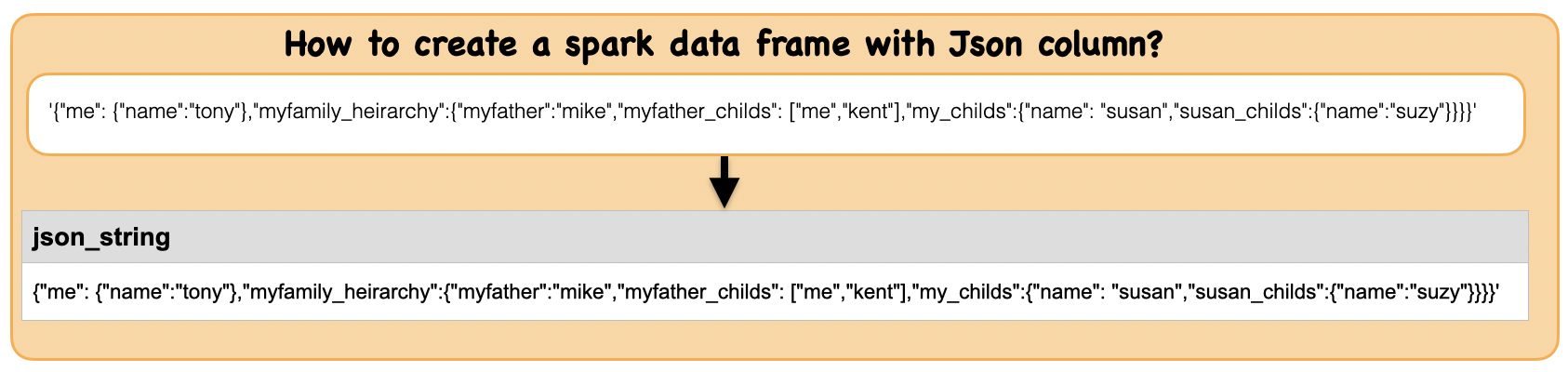
json_string = '{"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","kent"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}}'
rdd = spark.sparkContext.parallelize([json_string])
df_json = spark.createDataFrame([(json_string,)],["json_string"])
df_json.show(1,False)
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
|json_string |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
|{"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","kent"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}}|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
df_json.printSchema()
root
|-- json_string: string (nullable = true)
1b. How to infer a schema in DDL format from a JSON string column ?¶
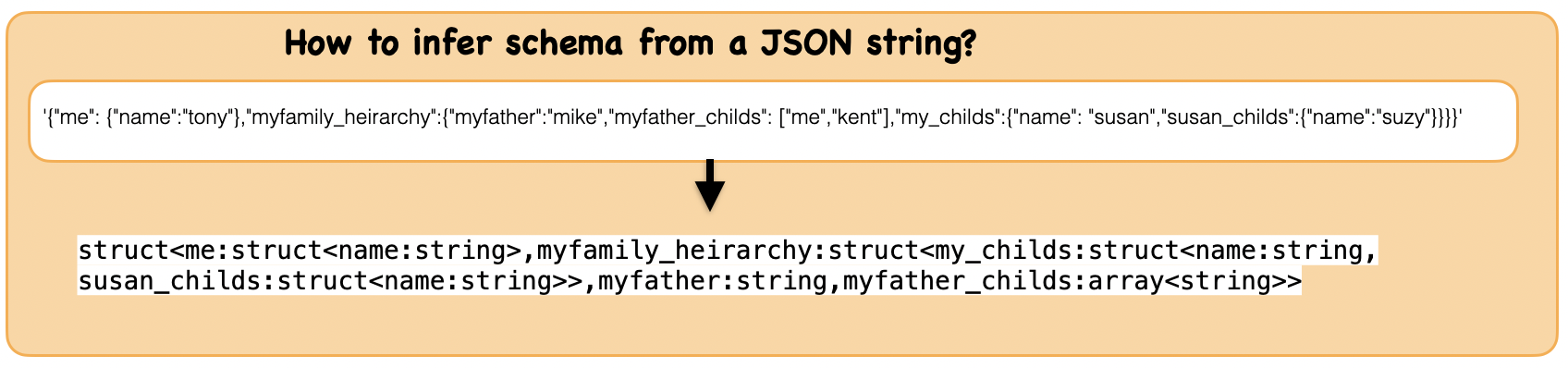
Lets first understand the syntax
Syntax
pyspark.sql.functions.schema_of_json(json, options={})
Parses a JSON string and infers its schema in DDL format.
Parameters
json – a JSON string or a string literal containing a JSON string.
options – options to control parsing. accepts the same options as the JSON datasource ‘’’
Input: Spark dataframe containing JSON string column
json_string = '{"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","kent"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}}'
rdd = spark.sparkContext.parallelize([json_string])
df_json = spark.createDataFrame([(json_string,)],["jsonstring"])
df_json.show(1,False)
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
|jsonstring |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
|{"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","kent"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}}|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
Output : Spark dataframe containing individual JSON elements
from pyspark.sql.functions import schema_of_json,col
schema = schema_of_json(json_string, {'allowUnquotedFieldNames':'true'})
schema = schema_of_json(json_string)
df_json.select(schema.alias("schema")).collect()[0][0]
'struct<me:struct<name:string>,myfamily_heirarchy:struct<my_childs:struct<name:string,susan_childs:struct<name:string>>,myfather:string,myfather_childs:array<string>>>'
schema
Column<b'schema_of_json({"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","kent"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}})'>
1c. How to extract elements from JSON column ?¶
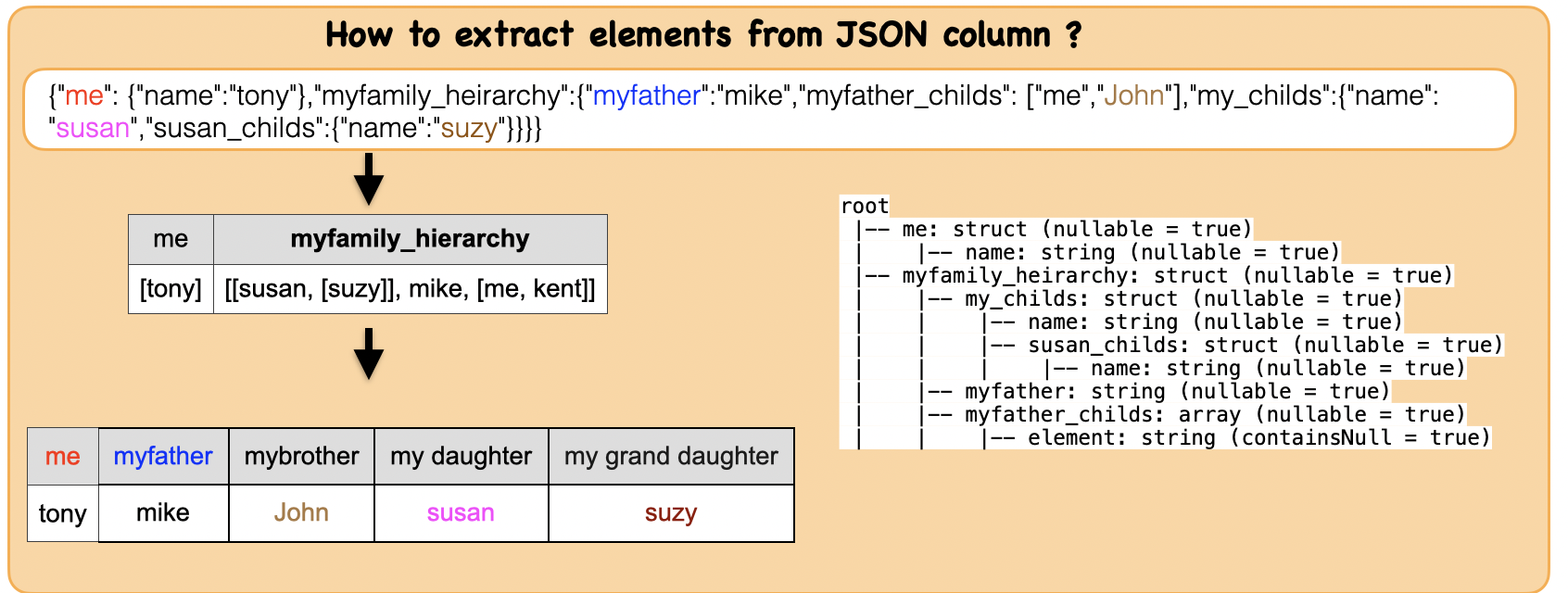
Input: Spark dataframe containing JSON column
json_string = '{"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","John"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}}'
rdd = spark.sparkContext.parallelize([json_string])
df_json = spark.read.json(rdd)
df_json.show(1,False)
df_json.printSchema()
+------+-----------------------------------+
|me |myfamily_heirarchy |
+------+-----------------------------------+
|[tony]|[[susan, [suzy]], mike, [me, John]]|
+------+-----------------------------------+
root
|-- me: struct (nullable = true)
| |-- name: string (nullable = true)
|-- myfamily_heirarchy: struct (nullable = true)
| |-- my_childs: struct (nullable = true)
| | |-- name: string (nullable = true)
| | |-- susan_childs: struct (nullable = true)
| | | |-- name: string (nullable = true)
| |-- myfather: string (nullable = true)
| |-- myfather_childs: array (nullable = true)
| | |-- element: string (containsNull = true)
Output : Spark dataframe containing individual JSON elements
from pyspark.sql.functions import col
df_json_ele = df_json.select("me.name","myfamily_heirarchy.myfather",col("myfamily_heirarchy.myfather_childs").getItem(1).alias("mybrother"),
col("myfamily_heirarchy.my_childs.name").alias("my daughter"),
col("myfamily_heirarchy.my_childs.susan_childs.name").alias("my grand daughter"))
df_json_ele.toPandas()
| name | myfather | mybrother | my daughter | my grand daughter | |
|---|---|---|---|---|---|
| 0 | tony | mike | John | susan | suzy |
Summary:
print("Input ", "Output")
display_side_by_side(df_json.toPandas(),df_json_ele.toPandas())
Input Output
| me | myfamily_heirarchy |
|---|---|
| (tony,) | ((susan, (suzy,)), mike, [me, John]) |
| name | myfather | mybrother | my daughter | my grand daughter |
|---|---|---|---|---|
| tony | mike | John | susan | suzy |
1d. How to convert a data frame to JSON string?¶

Lets first understand the syntax
Syntax
toJSON(use_unicode=True)
Converts a DataFrame into a RDD of string. Each row is turned into a JSON document as one element in the returned RDD.
‘’’
Input: Spark data frame
df_mul = spark.createDataFrame([('John', 'Seattle', 60, True, 1.7, '1960-01-01'),
('Tony', 'Cupertino', 30, False, 1.8, '1990-01-01'),
('Mike', 'New York', 40, True, 1.65, '1980-01-01')],['name', 'city', 'age', 'smoker','height', 'birthdate'])
df_mul.show()
+----+---------+---+------+------+----------+
|name| city|age|smoker|height| birthdate|
+----+---------+---+------+------+----------+
|John| Seattle| 60| true| 1.7|1960-01-01|
|Tony|Cupertino| 30| false| 1.8|1990-01-01|
|Mike| New York| 40| true| 1.65|1980-01-01|
+----+---------+---+------+------+----------+
Output : Spark data frame with a struct column with a new element added
df_mul.toJSON(use_unicode=True).collect()
['{"name":"John","city":"Seattle","age":60,"smoker":true,"height":1.7,"birthdate":"1960-01-01"}',
'{"name":"Tony","city":"Cupertino","age":30,"smoker":false,"height":1.8,"birthdate":"1990-01-01"}',
'{"name":"Mike","city":"New York","age":40,"smoker":true,"height":1.65,"birthdate":"1980-01-01"}']
df_mul.repartition(1).write.json("/Users/deepak/Documents/json1.json",mode="overwrite")
1e. How to convert JSON string column into StructType column?¶
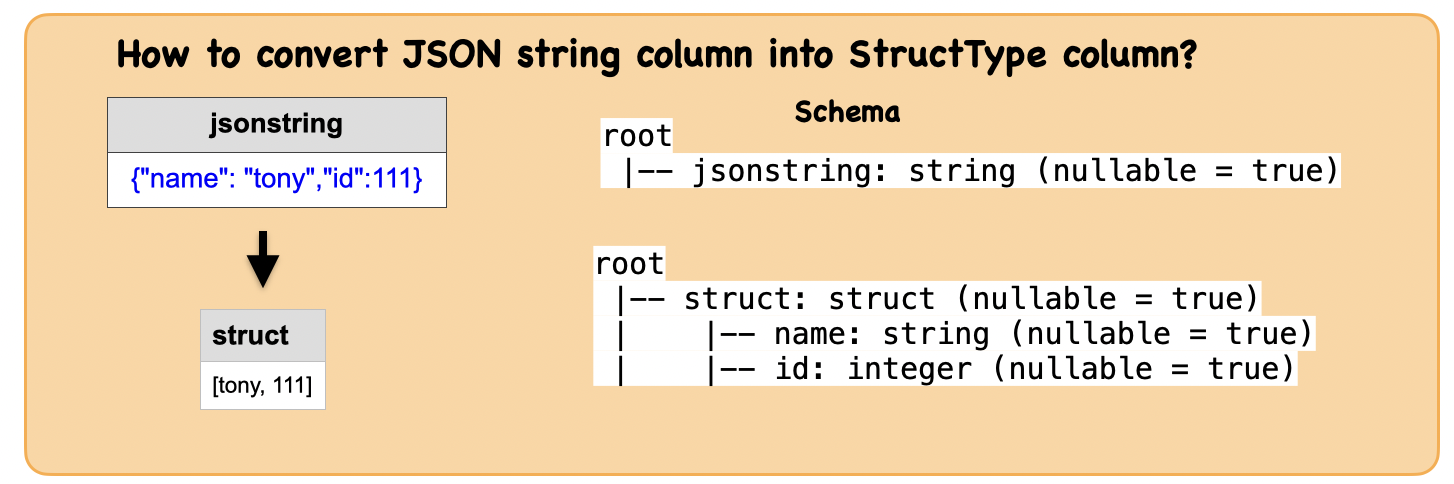
Lets first understand the syntax
Syntax
pyspark.sql.functions.from_json(col, schema, options={})
Parses a column containing a JSON string into a MapType with StringType as keys type, StructType or ArrayType with the specified schema. Returns null, in the case of an unparseable string.
Parameters
col – string column in json format
schema – a StructType or ArrayType of StructType to use when parsing the json column. options – options to control parsing. accepts the same options as the json datasource ‘’’
Input: Spark data frame with a JSON string column
from pyspark.sql.types import *
data = [('{"name": "tony","id":111}',)]
schema1 = StructType([StructField("name", StringType()), StructField("id", IntegerType())])
schema2 = "name string, id int"
df = spark.createDataFrame(data, ["jsonstring"])
df.show(1,False)
df.printSchema()
+-------------------------+
|jsonstring |
+-------------------------+
|{"name": "tony","id":111}|
+-------------------------+
root
|-- jsonstring: string (nullable = true)
Output : Spark data frame with a struct column
from pyspark.sql.functions import from_json
df_stru = df.select(from_json(df.jsonstring, schema1).alias("struct"))
df.select(from_json(df.jsonstring, schema2).alias("struct")).show()
df_stru.printSchema()
+-----------+
| struct|
+-----------+
|[tony, 111]|
+-----------+
root
|-- struct: struct (nullable = true)
| |-- name: string (nullable = true)
| |-- id: integer (nullable = true)
from pyspark.sql.functions import to_json
df_jsonstroing = df_stru.select(to_json(df_stru.struct))
df_jsonstroing.show(1, False)
df_stru.select(to_json(df_stru.struct)).dtypes
+------------------------+
|to_json(struct) |
+------------------------+
|{"name":"tony","id":111}|
+------------------------+
[('to_json(struct)', 'string')]
Summary:
print("input ", "output")
display_side_by_side(df.toPandas(),df.select(from_json(df.jsonstring, schema1).alias("struct")).toPandas())
input output
| jsonstring |
|---|
| {"name": "tony","id":111} |
| struct |
|---|
| (tony, 111) |
1f. How to convert JSON string column into MapType column?¶
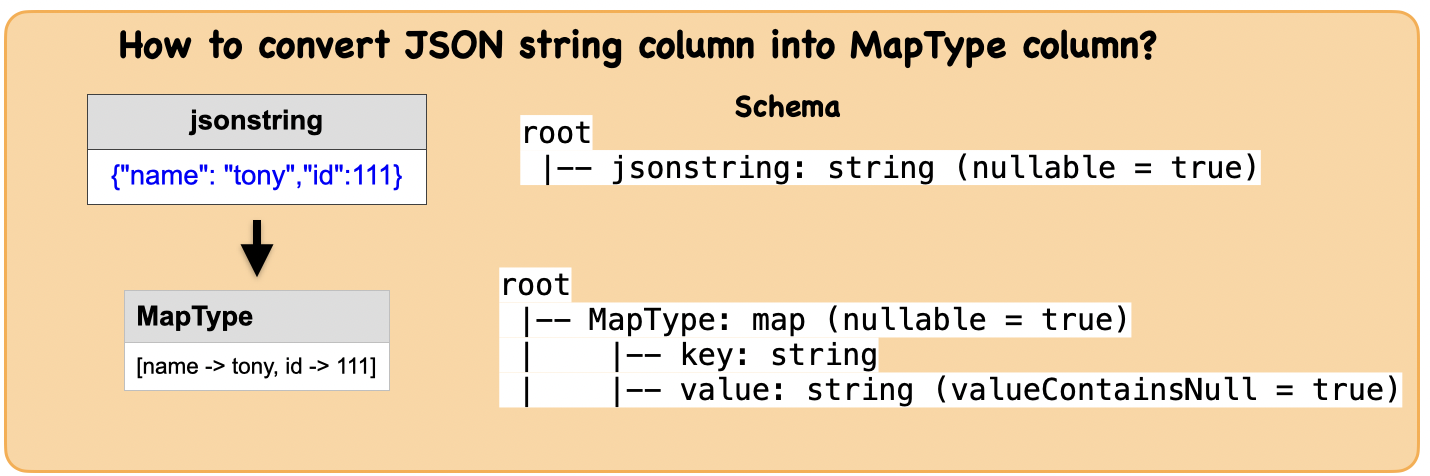
Input: Spark data frame with a JSON string column
from pyspark.sql.types import *
data = [('{"name": "tony","id":111}',)]
schema = StructType([StructField("name", StringType()), StructField("id", IntegerType())])
df = spark.createDataFrame(data, [ "jsonstring"])
df.show(1,False)
df.printSchema()
+-------------------------+
|jsonstring |
+-------------------------+
|{"name": "tony","id":111}|
+-------------------------+
root
|-- jsonstring: string (nullable = true)
Output : Spark dataframe with a MapType column
df_map = df.select(from_json(df.jsonstring, "MAP<string,string>").alias("MapType"))
df_map.show(1,False)
df_map.printSchema()
+-------------------------+
|MapType |
+-------------------------+
|[name -> tony, id -> 111]|
+-------------------------+
root
|-- MapType: map (nullable = true)
| |-- key: string
| |-- value: string (valueContainsNull = true)
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_map.toPandas())
print(df.dtypes,df_map.dtypes)
Input Output
| jsonstring |
|---|
| {"name": "tony","id":111} |
| MapType |
|---|
| {'name': 'tony', 'id': '111'} |
[('jsonstring', 'string')] [('MapType', 'map<string,string>')]
1g. How to convert JSON string column into ArrayType column?¶
Input: Spark data frame with a JSON string column
from pyspark.sql.types import *
data = [('[{"name": "tony","id":111}]',)]
schema = StructType([StructField("name", StringType()), StructField("id", IntegerType())])
df = spark.createDataFrame(data, [ "jsonstring"])
df.show(1,False)
df.printSchema()
+---------------------------+
|jsonstring |
+---------------------------+
|[{"name": "tony","id":111}]|
+---------------------------+
root
|-- jsonstring: string (nullable = true)
Output : Spark dataframe with a ArrayType column
schema = ArrayType(StructType([StructField("name", StringType()), StructField("id", IntegerType())]))
df_arr = df.select(from_json(df.jsonstring, schema).alias("ArrayType"))
df_arr.show(1,False)
df_arr.printSchema()
+-------------+
|ArrayType |
+-------------+
|[[tony, 111]]|
+-------------+
root
|-- ArrayType: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- name: string (nullable = true)
| | |-- id: integer (nullable = true)
schema = ArrayType(StructType([StructField("name", StringType()), StructField("id", IntegerType())]))
df_arr = df.select(from_json(df.jsonstring, schema).alias("ArrayType"))
df_arr.show(1,False)
print(df_arr.printSchema())
+-------------+
|ArrayType |
+-------------+
|[[tony, 111]]|
+-------------+
root
|-- ArrayType: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- name: string (nullable = true)
| | |-- id: integer (nullable = true)
None
Summary:
print("Input ", "Output")
display_side_by_side(df.toPandas(),df_arr.toPandas())
print(df.dtypes,df_arr.dtypes)
Input Output
| jsonstring |
|---|
| [{"name": "tony","id":111}] |
| ArrayType |
|---|
| [(tony, 111)] |
[('jsonstring', 'string')] [('ArrayType', 'array<struct<name:string,id:int>>')]
1h. How to convert StructType/MapType/ArrayType column into JSON string?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.to_json(col, options={})
Converts a column containing a StructType, ArrayType or a MapType into a JSON string. Throws an exception, in the case of an unsupported type.
Parameters
col – name of column containing a struct, an array or a map.
options – options to control converting. accepts the same options as the JSON datasource. Additionally the function supports the pretty option which enables pretty JSON generation. ‘’’
Input : Spark data frame with a struct column
data = [([{"name": "Alice"}, {"name": "Bob"}],)]
df = spark.createDataFrame(data, ["ArrayofMap"])
df.show(1,False)
df.printSchema()
+--------------------------------+
|ArrayofMap |
+--------------------------------+
|[[name -> Alice], [name -> Bob]]|
+--------------------------------+
root
|-- ArrayofMap: array (nullable = true)
| |-- element: map (containsNull = true)
| | |-- key: string
| | |-- value: string (valueContainsNull = true)
from pyspark.sql.functions import to_json
df.select(to_json(df.ArrayofMap).alias("json")).show(1,False)
df.select(to_json(df.ArrayofMap).alias("json")).printSchema()
+---------------------------------+
|json |
+---------------------------------+
|[{"name":"Alice"},{"name":"Bob"}]|
+---------------------------------+
root
|-- json: string (nullable = true)
Summary:
print("input ", "output")
display_side_by_side(df.toPandas(),df.select(to_json(df.ArrayofMap).alias("json")).toPandas())
input output
| ArrayofMap |
|---|
| [{'name': 'Alice'}, {'name': 'Bob'}] |
| json |
|---|
| [{"name":"Alice"},{"name":"Bob"}] |
1i. How to extract JSON object from a JSON string column?¶
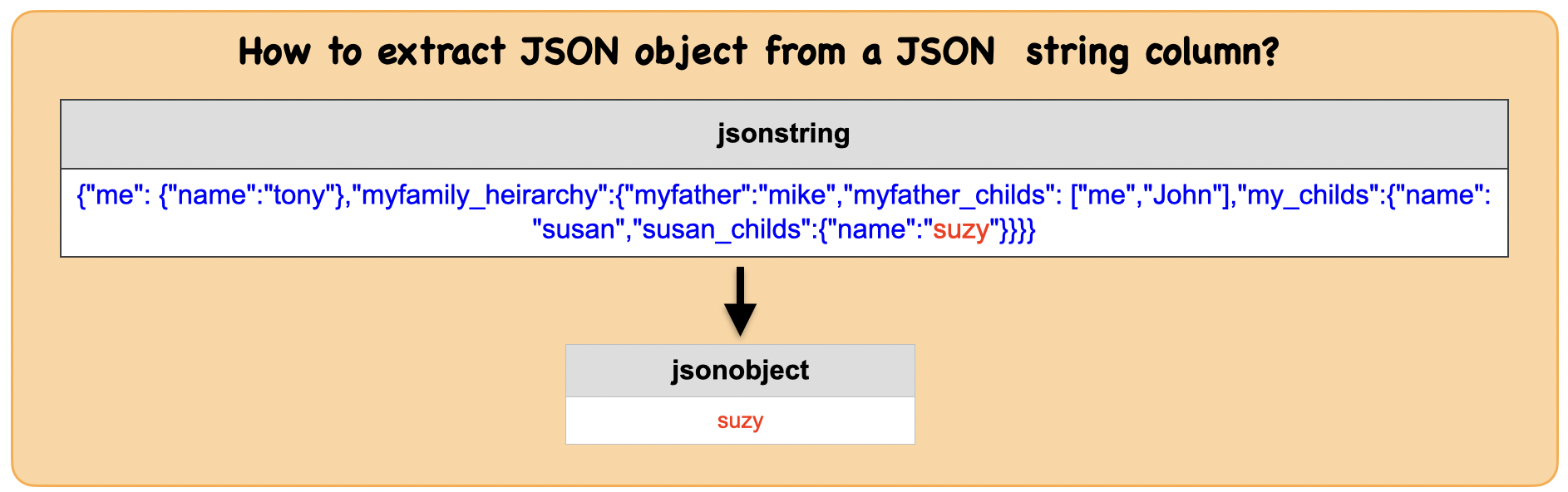
Lets first understand the syntax
Syntax
pyspark.sql.functions.get_json_object(col, path)
Extracts json object from a json string based on json path specified, and returns json string of the extracted json object. It will return null if the input json string is invalid.
Parameters
col – string column in json format
path – path to the json object to extract ‘’’
Input: Spark data frame with a JSON string column
json_string = '{"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","John"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}}'
df_json = spark.createDataFrame([(json_string,)],["jsonstring"])
df_json.show(1,False)
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
|jsonstring |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
|{"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","John"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}}|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
Output : Spark dataframe with column containing a JSON object
from pyspark.sql.functions import get_json_object
df_obj = df_json.select(get_json_object(df_json.jsonstring , "$.myfamily_heirarchy.my_childs.susan_childs.name").alias("jsonobject"))
df_obj.show(1,False)
df_obj.dtypes
+----------+
|jsonobject|
+----------+
|suzy |
+----------+
[('jsonobject', 'string')]
Summary:
print("Input ", "Output")
display_side_by_side(df_json.toPandas(),df_obj.toPandas())
Input Output
| jsonstring |
|---|
| {"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","John"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}} |
| jsonobject |
|---|
| suzy |
1j. How to extract JSON objects based on list of field names?¶

Lets first understand the syntax
Syntax
pyspark.sql.functions.json_tuple(col, *fields)
Creates a new row for a json column according to the given field names.
Parameters
col – string column in json format
fields – list of fields to extract ‘’’
Input: Spark data frame with a JSON string column
json_string = '{"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","John"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}}'
df_json = spark.createDataFrame([(json_string,)],["jsonstring"])
df_json.show(1,False)
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
|jsonstring |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
|{"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","John"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}}|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
Output : Spark dataframe with a MapType column
from pyspark.sql.functions import json_tuple
df_out = df_json.select(json_tuple(df_json.jsonstring, 'me', 'myfamily_heirarchy',))
df_out.show(1,False)
+---------------+---------------------------------------------------------------------------------------------------------------+
|c0 |c1 |
+---------------+---------------------------------------------------------------------------------------------------------------+
|{"name":"tony"}|{"myfather":"mike","myfather_childs":["me","John"],"my_childs":{"name":"susan","susan_childs":{"name":"suzy"}}}|
+---------------+---------------------------------------------------------------------------------------------------------------+
Summary:
print("Input ", "Output")
display_side_by_side(df_json.toPandas(),df_out.toPandas())
Input Output
| jsonstring |
|---|
| {"me": {"name":"tony"},"myfamily_heirarchy":{"myfather":"mike","myfather_childs": ["me","John"],"my_childs":{"name": "susan","susan_childs":{"name":"suzy"}}}} |
| c0 | c1 |
|---|---|
| {"name":"tony"} | {"myfather":"mike","myfather_childs":["me","John"],"my_childs":{"name":"susan","susan_childs":{"name":"suzy"}}} |