

Chapter 15 : Aggregate Operations¶
Chapter Learning Objectives¶
Various aggregate operations on data frame.
Chapter Outline¶
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
from IPython.display import display_html
import pandas as pd
import numpy as np
def display_side_by_side(*args):
html_str=''
for df in args:
html_str+=df.to_html(index=False)
html_str+= "\xa0\xa0\xa0"*10
display_html(html_str.replace('table','table style="display:inline"'),raw=True)
space = "\xa0" * 10
import panel as pn
css = """
div.special_table + table, th, td {
border: 3px solid orange;
}
"""
pn.extension(raw_css=[css])
1a. DataFrame Aggregations¶
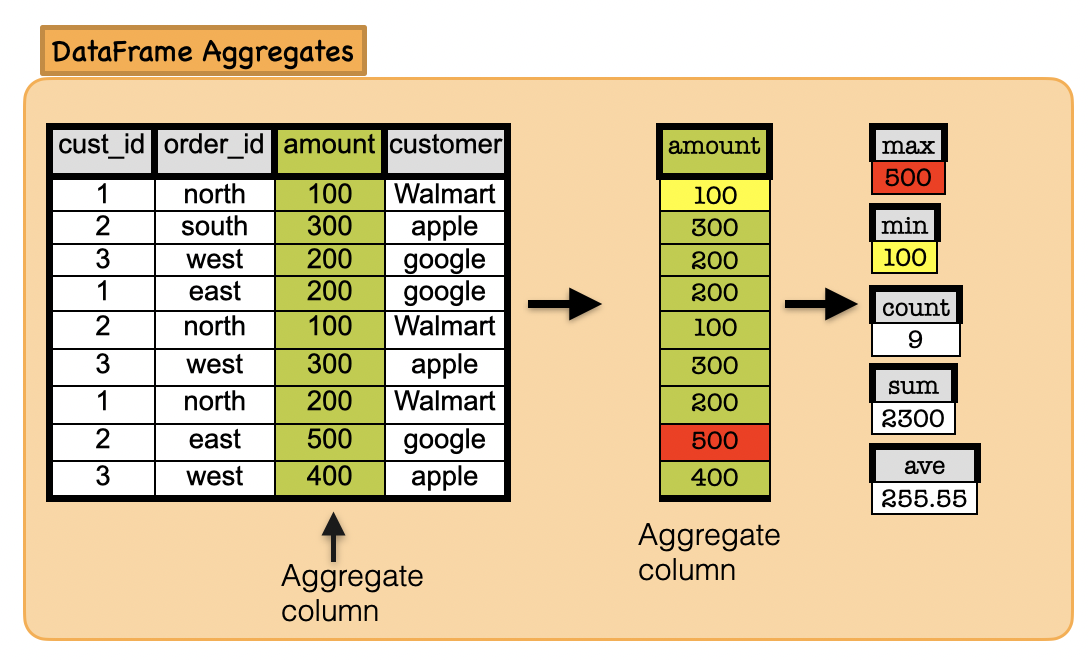
Lets first understand the syntax
Syntax
pyspark.sql.DataFrame.agg(*exprs)
Aggregate on the entire DataFrame without groups (shorthand for df.groupBy.agg()).
‘’’
Input: Spark dataframe¶
df = spark.createDataFrame([(1,"north",100,"walmart"),(2,"south",300,"apple"),(3,"west",200,"google"),
(1,"east",200,"google"),(2,"north",100,"walmart"),(3,"west",300,"apple"),
(1,"north",200,"walmart"),(2,"east",500,"google"),(3,"west",400,"apple"),],
["emp_id","region","sales","customer"])
df.show()#show(truncate=False)
+------+------+-----+--------+
|emp_id|region|sales|customer|
+------+------+-----+--------+
| 1| north| 100| walmart|
| 2| south| 300| apple|
| 3| west| 200| google|
| 1| east| 200| google|
| 2| north| 100| walmart|
| 3| west| 300| apple|
| 1| north| 200| walmart|
| 2| east| 500| google|
| 3| west| 400| apple|
+------+------+-----+--------+
print(df.sort('customer').toPandas().to_string(index=False))#show()
emp_id region sales customer
2 south 300 apple
3 west 300 apple
3 west 400 apple
3 west 200 google
1 east 200 google
2 east 500 google
1 north 100 walmart
2 north 100 walmart
1 north 200 walmart
df.agg({"sales": "sum"}).show()
+----------+
|sum(sales)|
+----------+
| 2300|
+----------+
df.agg({"sales": "min"}).show()
+----------+
|min(sales)|
+----------+
| 100|
+----------+
df.agg({"sales": "max"}).show()
+----------+
|max(sales)|
+----------+
| 500|
+----------+
df.agg({"sales": "count"}).show()
+------------+
|count(sales)|
+------------+
| 9|
+------------+
df.agg({"sales": "mean"}).show()
+------------------+
| avg(sales)|
+------------------+
|255.55555555555554|
+------------------+
df.agg({"sales": "mean","customer":"count"}).show()
+------------------+---------------+
| avg(sales)|count(customer)|
+------------------+---------------+
|255.55555555555554| 9|
+------------------+---------------+
1b. DataFrame Aggregations¶
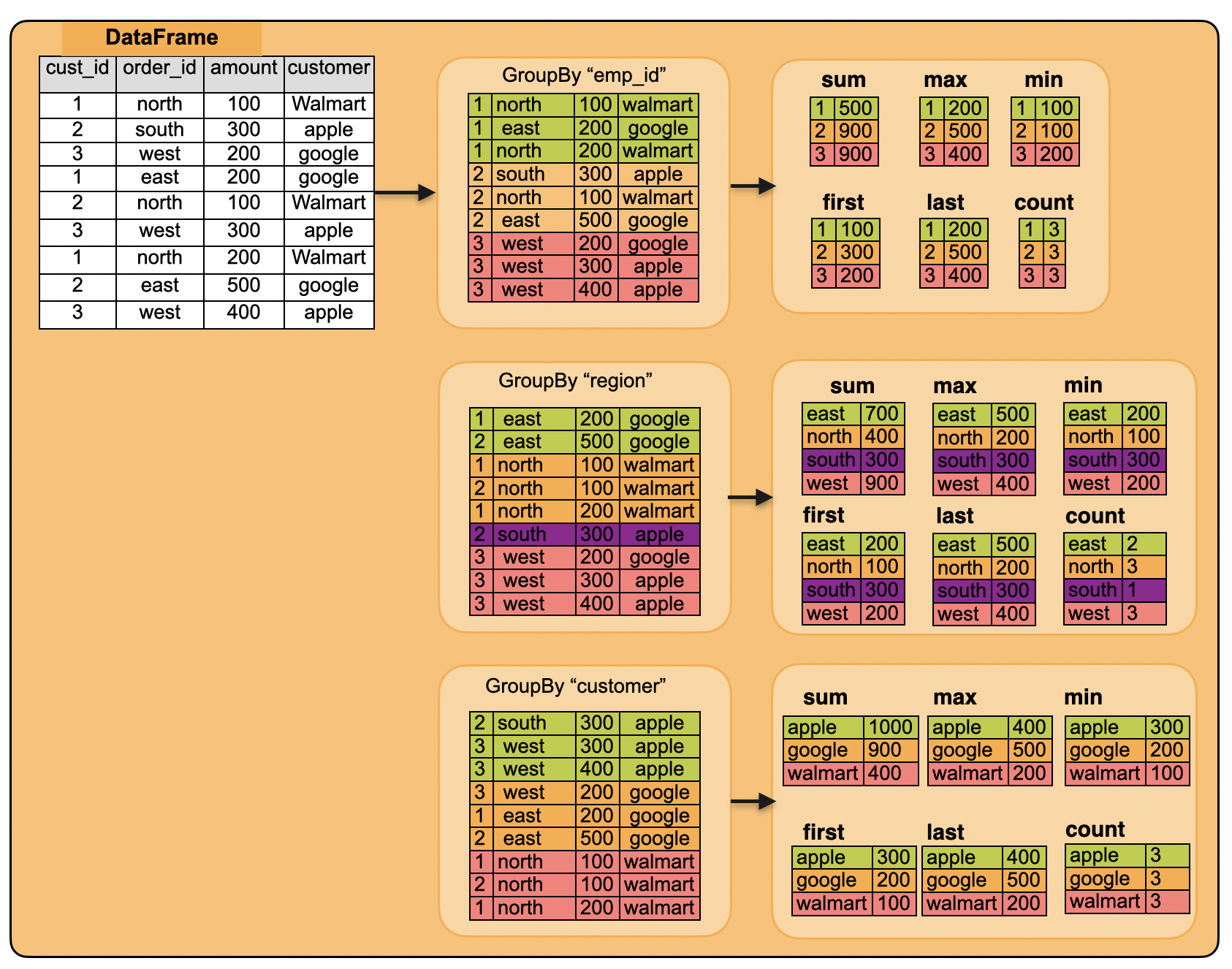
df.groupby("emp_id").agg({"sales": "sum"}).orderBy('emp_id').toPandas()#show()
| emp_id | sum(sales) | |
|---|---|---|
| 0 | 1 | 500 |
| 1 | 2 | 900 |
| 2 | 3 | 900 |
df.groupby("emp_id").agg({"sales": "max"}).orderBy('emp_id').toPandas()
| emp_id | max(sales) | |
|---|---|---|
| 0 | 1 | 200 |
| 1 | 2 | 500 |
| 2 | 3 | 400 |
df.groupby("emp_id").agg({"sales": "last"}).orderBy('emp_id').toPandas()
| emp_id | last(sales) | |
|---|---|---|
| 0 | 1 | 200 |
| 1 | 2 | 500 |
| 2 | 3 | 400 |
df.groupby("region").agg({"sales": "sum"}).orderBy('region').show()
+------+----------+
|region|sum(sales)|
+------+----------+
| east| 700|
| north| 400|
| south| 300|
| west| 900|
+------+----------+
df.groupby("customer").agg({"sales": "sum"}).orderBy('customer').show()
+--------+----------+
|customer|sum(sales)|
+--------+----------+
| apple| 1000|
| google| 900|
| walmart| 400|
+--------+----------+